Automatic Speech Recognition
Transcription : Voice to Text
Level AI’s speech-to-text engine converts billions of spoken words into accurate transcripts each month. It's powered by a proprietary seven-stage AI pipeline and dedicated audio servers for real-time performance.



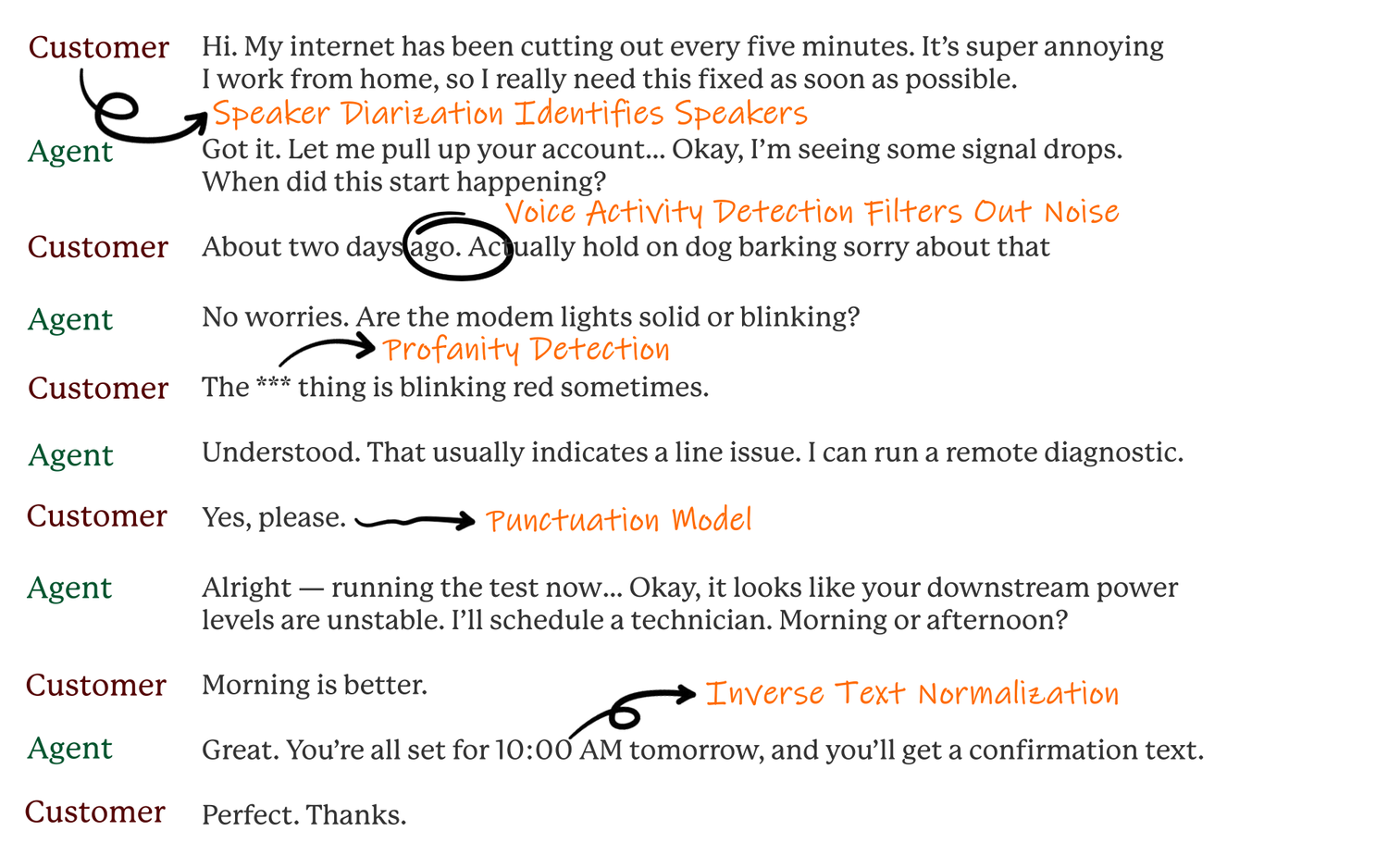
Seven Core Models
Filters speech from noise and silence, focusing only on spoken words.
Identifies basic sounds and letters spoken, the building blocks of words.
Arranges sounds into naturally flowing sentences.
Checks for and removes inappropriate language.
Identifies and tracks when different speakers talk in a conversation.
Adds correct punctuation and capitalization for easy-to-read text.
Formats numbers and special terms (three and a half dollars -> $3.50).
Speech Recognition Pipeline in Action
Level AI's speech recognition pipeline turns raw transcription text output into a readable, professionally formatted document.




Voice Recognition
Voice Activity AI precisely identifies speech and filters out background noise.
- Speaker Separation: Differentiates each speaker’s voice.
- Speech Detection: Distinguishes speech from silence.
- Timestamp Accuracy: Marks precise start and end points of speech.


How Speech Becomes Text
This system listens to spoken words, identifying the individual sounds and letters that form them.
- Audio Intake: The system receives and prepares the raw sound.
- Acoustic Clues: Detects patterns in pitch, volume, and rhythm.
- Text Prediction: Clues are translated to letters and words.


Making Sense of Your Speech
Each client has a custom language model trained on their specific conversations. It learns the unique words and phrases of their industry and business.
- Sound Guesses: The system's initial phonetic predictions.
- Expert Interpretation: Inferred guesses by the Language model.
- Final Text: The words the system understood.


The Self-Learning Cycle
The AI learns by listening, interpreting, and generating its own practice exercises, improving continuously without human input and learning efficiently from all available audio.
- Audio Ingestion: Listens to and processes audio.
- Comprehension: Interprets intent and meaning.
- Auto-Practice: Generates its own training sessions.
- Continuous Learning: Improves accuracy over time.









