

Key takeaways
1. Traditional QA tools fail because they grade virtual agents on human empathy rather than technical execution
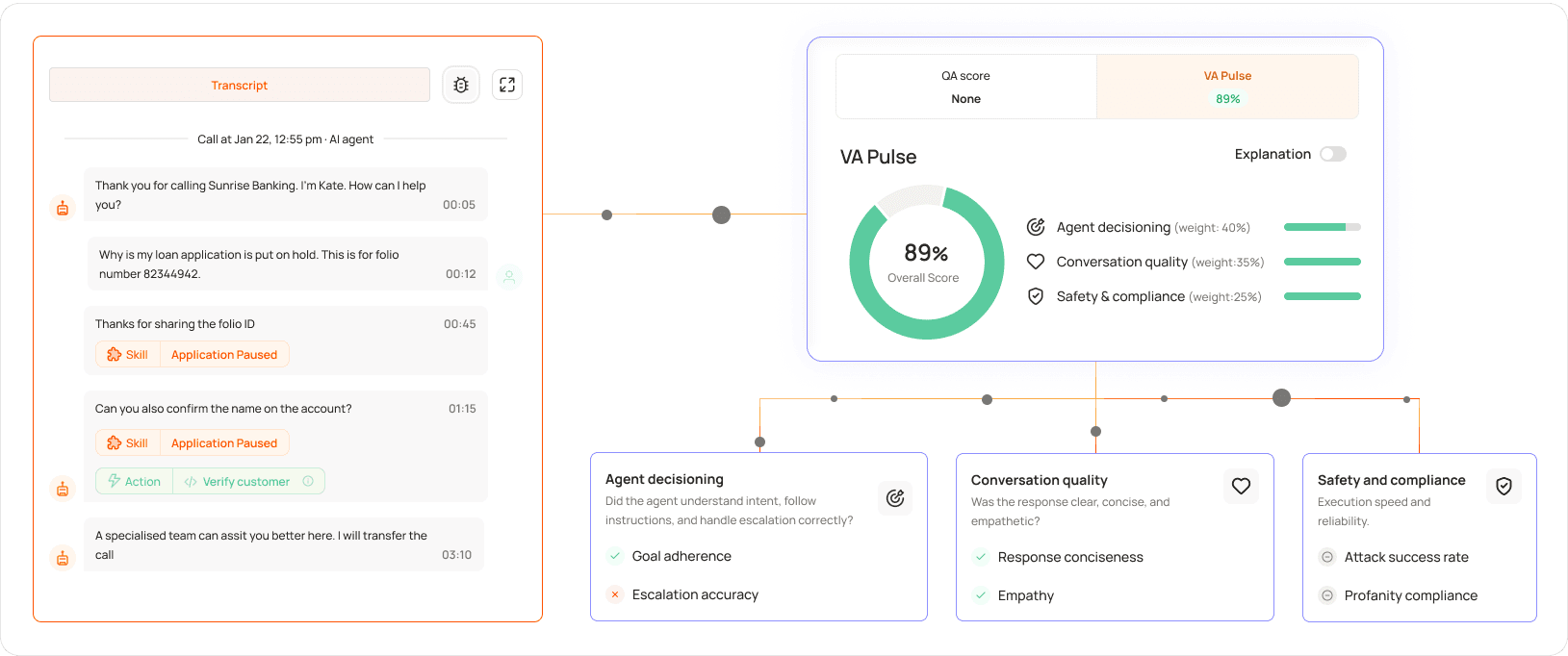
2. Level AI’s Virtual Agent Pulse solves this blind spot by automatically auditing bot interactions to score performance using three technical metrics:
Agent Decisioning (40% Score Weight): Measures logic, goal accuracy, and correct human escalation.
Performance & Safety (35% Score Weight): Monitors system latency and blocks prompt-injection risks.
Conversation Quality (25% Score Weight): Evaluates message conciseness and contextual help.
The Automation Blindspot
Every virtual agent platform on the market sells the exact same promise: deploy our bot, deflect your tickets, and watch your overhead drop. But here is the reality nobody talks about - once these bots go live, an ugly reality sets in.
In most enterprises, the AI engineering or digital product teams who build or procure the virtual agents are completely siloed from the contact center operations and QA teams responsible for customer experience. This fragmentation turns daily operations into a fragile guessing game. When an automated workflow breaks, it doesn’t trigger a clean alert on an IT dashboard. Instead, a customer support manager finds out from an angry escalation or a tanking CSAT score.
Because there is no unified scoring framework, diagnosing the issue becomes increasingly difficult. While the contact center teams pulls a broken transcript and points out that the bot failed to solve the customer's problem. Whereas, the AI engineering team looks at their server logs, sees successful API response code, and claims the bot is functioning perfectly.
And to piece together what actually happened, teams are forced to manually stitch third-party logging tools with contact center transcripts, parse raw database payloads, and build custom pipelines. Worse, teams are unable to evaluate conversation data effectively, and the operations leadership cannot tie bot behavior to actual business outcomes.
The root of the problem is that traditional QA tools leveraged by the contact center teams were built exclusively for human managers to evaluate human soft skills, grading things like tone and script compliance. But a virtual agent doesn't suffer from a bad attitude. It suffers from systemic technical failures. A bot will speak with perfect empathy while passing corrupted variables to the CRM, dropping customer intent mid-chat, or confidently fabricating a pricing policy out of thin air. Standard, text-based QA tools cannot surface these infrastructure drops. If the bot stays polite while trapped in a broken loop, human-centric QA platforms will still hand it a perfect score.
In order to make automation safe for production environments, teams must stop grading bots on rubrics relevant only for human-to-human conversations and start auditing them for system-level execution precision.
Bot Accountability Demands AI-Specific Calibration: What is Level AI’s VA Pulse?
We engineered VA Pulse to pull companies out of this automation blindspot of your digital workforce. It operates as an automated system that runs alongside the virtual agent interactions, analyzing every conversation transcript to compute a unified performance index.
Instead of searching for human communication habits, VA Pulse grades interactions based on AI-specific parameters. Instead of grading whether a bot used a polite corporate greeting, VA Pulse audits the bot-to-human conversations against the unique technical failure points - such tool execution or compliance rules, etc., that are valid only in an AI-driven environment.
For an honest, system-level baseline of how the automation is performing, Level AI’s VA Pulse framework scores every single interaction across three clear operational layers:
Agent Decisioning (40% Weight): This layer checks if your bot can handle automated reasoning and logic. It tracks ‘Goal Adherence Accuracy’ to prove the bot followed the explicit business rules outlined. It measures ‘Input Collection Efficiency’ which is an AI-specific metric that checks if the bot captured customer data cleanly in one shot, or if its phrasing dragged the user through a frustrating loop of repeated questions. Finally, it audits ‘Escalation Accuracy’ to guarantee the bot recognized its algorithmic limits and handed off the conversation to a human teammate precisely when required.
Performance & Safety (35% Weight): This layer monitors structural health and brand liability. The Pulse framework tracks backend response speed, instantly failing any interaction where the latency crosses a 2.5-second threshold. At the same time, it scores the transcript through a dedicated safety bucket built for generative AI risks, auditing Attack Success Rate (ASR) to verify if the bot successfully blocked malicious prompt-injection or jailbreak attempts, alongside strict profanity compliance.
Conversation Quality (25% Weight): Lastly, this layer uses lightweight semantic models to grade the layout of the output text. It evaluates ‘Response Conciseness’ to ensure the language model does not overwhelm users with walls of text, and balances it against ‘Response Empathy’ to ensure the automated response remains contextually helpful.
By embedding these AI-specific parameters directly into the engine, the system accurately grades production workflows while automatically adjusting the calculation whenever conversation paths vary.
Zero-Disruption Architecture: How VA Pulse Plugs Into Your Existing Stack
Deploying a brand-independent auditing framework does not require your IT teams to rebuild your automation layer or switch conversational AI providers. VA Pulse is engineered as an out-of-box, API-driven layer designed to monitor your digital workforce in parallel with your live production traffic.
The integration process follows a streamlined, non-intrusive path:
Universal Log Ingestion: VA Pulse connects via secure webhooks or native APIs directly to your current virtual agent platforms (such as Google Dialogflow, Amazon Lex, Microsoft Copilot, or custom LLM frameworks). It ingests raw conversation transcripts and metadata seamlessly via the ingestion pipeline set up.
Asynchronous Processing Pipeline: To protect customer experience, the system operates completely outside the live user-to-bot chat loop. The transcript parsing, semantic evaluation, and dynamic weight calculations happen asynchronously, meaning VA Pulse introduces exactly zero latency to your active customer interactions.
Unified Quality Dashboard: The resulting engineering-grade scores and AI-specific compliance flags are pushed directly to a central interface.
By separating the auditing engine from the conversational runtime, you achieve uncompromised, third-party governance across your entire automated footprint—without touching a single line of your bot's core workflow code.
How Level AI Leverages Enterprise QA Leadership to Drive Dynamic Bot Accountability
AI conversations change based on what the customer needs. On a straightforward billing check, a bot might resolve a query perfectly in three turns without ever needing to call an external API, verify an account number, or transfer the user to a human supervisor. Because basic analytics tools don't understand conversational context, they register those unused fields as failures, which unfairly drags down the bot's overall quality score.
VA Pulse eliminates this issue using automatic calculation rebalancing. When an interaction finishes, the system immediately identifies which metrics were actually relevant to that specific conversation path:
Eliminating Penalties: If a step did not need to happen, such as a routine interaction where a human transfer was never triggered - Level AI platform marks that metric as Not Applicable (N/A). Thereby making dynamic readjustments to performance scoring instead of penalizing the bot.
Ensuring Fair Weightages with Even Redistribution: VA Pulse’s framework drops irrelevant metrics entirely from the score calibration, and splits the remaining percentage weight evenly across the other active metrics in that category. This ensures the final quality percentage stays perfectly fair and completely reflective of actual performance.
Managing these dynamic data adjustments and parsing real-time conversational intent requires deep quality assurance expertise. Level AI is not an isolated agentic tool trying to patch together a basic analytics page from scratch. As the industry pioneer that defined modern, AI-driven contact center QA, we have spent years perfecting complex grading rubrics, calibration models, and large-scale textual analysis for enterprise CX operations. VA Pulse is the direct evolution of that expertise - an engine that can dynamically adjust weights without breaking compliance math because it is backed by years of baseline data. We have taken our mature, market-leading human QA engine and applied it directly to the automated workforce, giving businesses the most stable, mathematically reliable bot governance platform available today.
The Bottom-Line Business Case for AI-Specific Bot Quality Assurance
Treating virtual agents like black-boxed, self-correcting systems is a massive risk. When a virtual agent underperforms, a flawed prompt or a broken integration loop impacts thousands of customers simultaneously, scaling operational damage at a terrifying speed. Implementing a dedicated, independent QA framework tailored for AI-specific parameters delivers critical business impact with measurable bottom-line benefits:
Maximize Operational Efficiency and Containment: Human agents don't accidentally repeat the exact same troubleshooting script five times in a row, but bots do. By grading on parameters like Input Collection Efficiency, VA Pulse flags where confusing bot phrasing is forcing customers into frustrating back-and-forth loops. Fixing these loops shortens handle times and keeps customers from rage-quitting the chat, preventing thousands of unnecessary, high-cost escalations to your human agents.
Protected Brand Trust and Eliminated Legal Risk: Generative AI introduces unique failure modes, like factual hallucinations and prompt-injection risks that human agents are simply incapable of committing. Tracking AI-specific safety parameters like Attack Success Rate (ASR) ensures your bots aren't exposed to jailbreak attempts or inventing false corporate policies in real time. This gives your legal and compliance teams total peace of mind to keep automation live in highly regulated environments.
Uncompromised Operational Clarity: While third-party bot vendors promise high deflection rates, a closed chat window doesn't mean a solved problem- it could also mean a frustrated customer gave up. Calibrating your audits around Goal Adherence Accuracy strips away this scoring bias. VA Pulse guarantees transparent, objective data proving whether the AI actually resolved the issue or if it is just hiding bad CX behind vanity metrics.
Shifting your QA strategy to focus on these specialized technical layers removes the guesswork from automation. It gives enterprise operations teams the objective, engineering-grade data they need to safely scale workflows, optimize model performance, and protect the customer experience.
The Final Mandate: Move from Monitoring to Governance
The message for enterprise CX leaders is clear: your digital workforce cannot be left to grade its own homework. Legacy human rubrics are blind to systemic software bugs, and third-party bot vendor dashboards are incentivized to hide poor customer experiences behind inflated deflection rates.
Level AI’s VA Pulse shifts the paradigm from simple text tracking to engineering-grade system governance. By evaluating your virtual agents against technical, AI-specific parameters, and dynamically adjusting the scoring math to match fluid conversational paths, you protect your brand from generative liability while cleanly driving down human escalation costs.
Automation is only as powerful as the infrastructure keeping it accountable. It is time to eliminate the guesswork, pull your digital workforce out of the blindspot, and deploy the uncompromised, third-party oversight your operations demand.
See how Level AI helps enterprises evaluate, optimize, and improve virtual agent outcomes with actionable insights. Talk to us today →
Frequently asked questions
How do you know when your virtual agent is silently failing?
A. Most teams don't know until a customer complains. Without AI-native monitoring like VA Pulse, failures like dropped intent, corrupted variables, and broken escalation logic never appear on any dashboard. The bot keeps responding politely while producing wrong outcomes, earning perfect QA scores all the while.
Why can't we just use our existing QA scorecard for virtual agents?
Existing scorecards evaluate human behaviors like empathy, tone, and script compliance. Virtual agents don't have attitudes; they have system failures. A bot can score 100% on a human rubric while passing corrupted data to your CRM or fabricating a pricing policy. AI-specific parameters like Input Collection Efficiency and Escalation Accuracy are what actually catch these failures.
What is a good latency benchmark for virtual agents in production?
VA Pulse uses a hard 2.5-second backend response threshold where any interaction that crosses this is automatically flagged as a failure. Industry best practice targets under 2 seconds for chat and under 1.5 seconds for voice to keep conversations natural.
How do you protect a virtual agent from prompt injection or jailbreak attempts?
VA Pulse tracks Attack Success Rate as part of its safety scoring, auditing every conversation to verify whether the bot blocked manipulation attempts. Companies should also implement guardrails at the model level, since prompt injection and jailbreak attempts are among the fastest-growing risks in production virtual agent environments.
How is the containment rate different from the actual virtual agent performance?
Containment rate only measures whether the bot kept a user in the automated flow, not whether it resolved their issue correctly. A bot can show high containment while silently mishandling intent, dropping data, or looping users in broken flows. VA Pulse's Goal Adherence and Input Collection metrics go deeper to surface the true quality of resolution.


