

In customer experience, a noticeable delay in a virtual agent’s response mirrors the frustrating silence in human conversation—instantly eroding trust. This hesitation changes a helpful interaction into a jarring, impersonal ordeal, leading customers to perceive they are speaking to a ‘robot.’ This undermines trust and drives customers back to human support instead of virtual agents.
For Level AI, low latency (i.e., the time it takes for the bot to respond after the user has finished speaking) is not merely a technical metric; it is the non-negotiable bedrock of confident, human-quality AI interactions. It is the difference between a user feeling heard and understood, or feeling ignored and stuck. Our internal benchmark is ambitious: maintaining a latency of less than 2 seconds for all bot responses. This aligns with external benchmarks for when delays become perceptible in natural human conversation.
Deconstructing the delay: layers of the virtual agent stack
To achieve such precision, it’s crucial to understand where latency originates. A user’s query doesn’t just ‘arrive’ at a virtual agent; instead the interaction travels through several tightly connected layers, each with its own potential for delay:
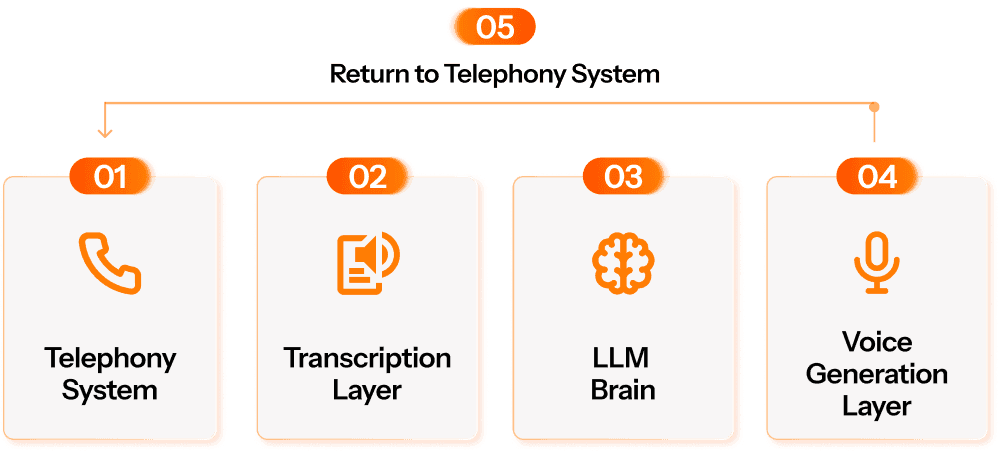
Telephony system: The moment a user speaks, their audio travels through the telephony provider and into the system.
Transcription layer: The incoming audio is processed and converted into text. This happens in buffered chunks, which introduces natural pauses as the system waits for enough audio to work with.
The LLM brain: The text is then handed off to the core intelligence, powered by Large Language Models, which processes it to understand intent, formulate a response, and apply guardrails to ensure safe and appropriate responses. Although we refer to this layer as a single brain, it involves multiple steps behind the scenes.
Voice generation layer: Once the LLM produces a response, a text-to-speech engine transforms the LLM’s text response back into natural-sounding speech that can be played back to the user.
Telephony system (return): And finally, the synthesized voice is sent back through the telephony provider to the user device.
Latency primarily stems from processing and network delays, as data travels across networks and servers, undergoing complex computations at each of these stages. Each of these five layers has a strict latency budget, and any deviation can impact the overall experience.
Navigating the technical nuances
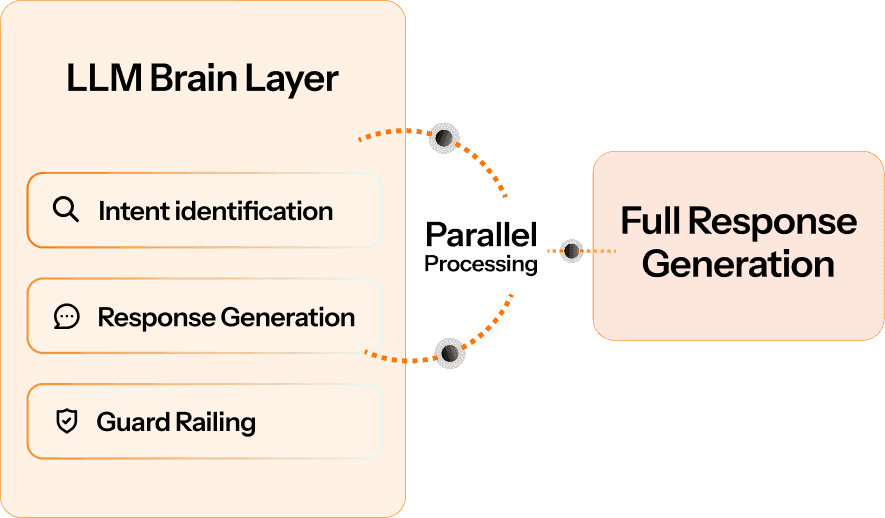
The ‘LLM Brain’ layer, for instance, involves intricate internal stages like intent identification, response generation, and guard railing. Optimizing these processes requires precise architectural decisions, such as running processes in parallel, where different parts work simultaneously rather than sequentially – so that the LLM engine is able to function as a highly efficient multi-tasking core.
Network optimization involves strategically placing components that need to communicate closer together in the infrastructure to minimize travel time. Additionally external customer systems, such as CRM or Contact Center Agent (CCA) integrations, can introduce their own latencies. While Level AI does not control these external components, our approach integrates intelligent conversational design such as preemptive ‘wait’ prompts, background music during transfers and more to manage perceived latency – all while ensuring a smooth, interruption-free end-user experience.
The strategic fix: Level AI’s engineered advantage
The pursuit of low latency is not merely about speed; it’s about architectural integrity and strategic control. At Level AI, we tackle these challenges with a differentiated approach:
Owned infrastructure for core processing: Unlike many platforms that rely heavily on public APIs and third-party vendors for critical functions, Level AI hosts its own infrastructure for fundamental layers like telephony and transcription, and uses controlled managed services to fine-tune parameters like buffer length, transcription breaking points, and other processing behaviors.. This ownership ensures greater control over processing times and data flow, eliminating unnecessary ‘black box’ security risks and enabling speed optimization from the ground up.
Smart model deployment with specialized SLMs: Latency often increases with model size and complexity. Level AI addresses this by orchestrating smart model deployment. We leverage 8 proprietary Small Language Models (SLMs) specialized for CX tasks like Transcription, Redaction, Auto-QA, and Intent Detection. These efficient SLMs handle high-volume, routine tasks quickly and cost-effectively while reserving larger, more powerful models for scenarios where nuanced reasoning is absolutely critical. This strategic model selection, backed by extensive internal testing of major models (e.g., Gemini, Claude, and GPT series) for precise latency measurement, ensures the best possible speed-to-accuracy trade-offs.
Parallel processing in the ‘LLM Brain’: To mitigate delays in complex decision-making, Level AI’s architecture is designed to run core functions in parallel. Intent detection, response generation, guard railing, and tool calling are executed simultaneously through non-blocking implementations. This is akin to a pit crew where all technicians work on different parts of a car at the same time, rather than one after another, helping save valuable milliseconds.
Optimized knowledge base retrieval: For queries requiring knowledge base lookups, Level AI has built a highly streamlined retrieval pipeline. We utilize state-of-the-art vector search databases that employ multiple layers of intelligent caching mechanisms, keep critical data in memory, and use fast and accurate embedding models. This ensures document retrieval is lightning-fast, often performing steps preemptively or in parallel to minimize wait times. Think of it as a library with an instant, perfectly indexed catalog, where you can find the exact book you need without searching a single shelf.
Unified AI architecture & end-to-end visibility: Level AI’s unified AI architecture means automation, insights and QA live on one platform. This consolidated stack provides full visibility across the system, allowing us to monitor over 20 metrics per layer with internal SLAs (P95, P75, P50 percentiles). This deep observability enables us to proactively identify latency breaches, precisely plan for capacity, and continually fine-tune performance. The result? An intelligent system that ensures reliability and performance at scale.
Human quality AI for perceived latency: Beyond technical optimization, Level AI balances system speed with intelligent experience design. For complex scenarios like chained API calls, we use intelligent conversational design, such as brief hold prompts to manage user expectations and ensure the perceived latency feels natural and human-like. This approach helps maintain user trust and prevent disengagement.
The bigger picture: AI that builds trust
Ultimately, Level AI’s commitment to engineered low latency is more than a technical achievement; it is a strategic imperative for delivering truly human-quality AI experiences. By owning critical infrastructure, leveraging specialized SLMs, optimizing for parallel processing, and maintaining end-to-end visibility across a unified architecture, Level AI ensures that every virtual agent interaction is seamless, confident, and deeply aligned with how people naturally expect conversations to flow. This foundational approach eliminates the unnatural gaps, building trust and driving superior customer outcomes.

