

What it costs when customers have to say it twice: we analyzed 33million conversations to quantify the impact starting over
This article is part of The Conversation Lab, where we publish short data stories from customer conversations. We analyze interaction patterns across our customer base and share what we find with CX leaders who need stronger signals than sampled QA and survey responses alone.
When customer reaches out around an issue, say a billing charge, she explains the issue, attaches a screenshot, and gets a reply saying it's been escalated. Too often, the ticket is resolved but the issue might come back later, or have only been partially handled. So she opens a new ticket, re-explains the issue to a different agent, and re-attaches the same screenshot.
Everything she did the first time transferred nothing. She had to restart from zero.
That experience is happening at scale, and the industry's biggest investment trend is making it worse. According to Gartner, 91% of customer service leaders reported executive pressure to implement AI in 2026. The volume of AI-handled interactions is growing fast, and the headline metric most vendors lead with is deflection rate — the share of interactions that never reach a human agent.
But the gap between deflection and resolution is where the problem lives. Gartner-sourced research shows AI deflects more than 45% of incoming customer queries, but only about 14% reach full self-service resolution. That 31-point gap represents interactions that were touched by automation, counted as handled, and left unresolved… producing exactly the kind of thread failure that sends a customer back to start over.
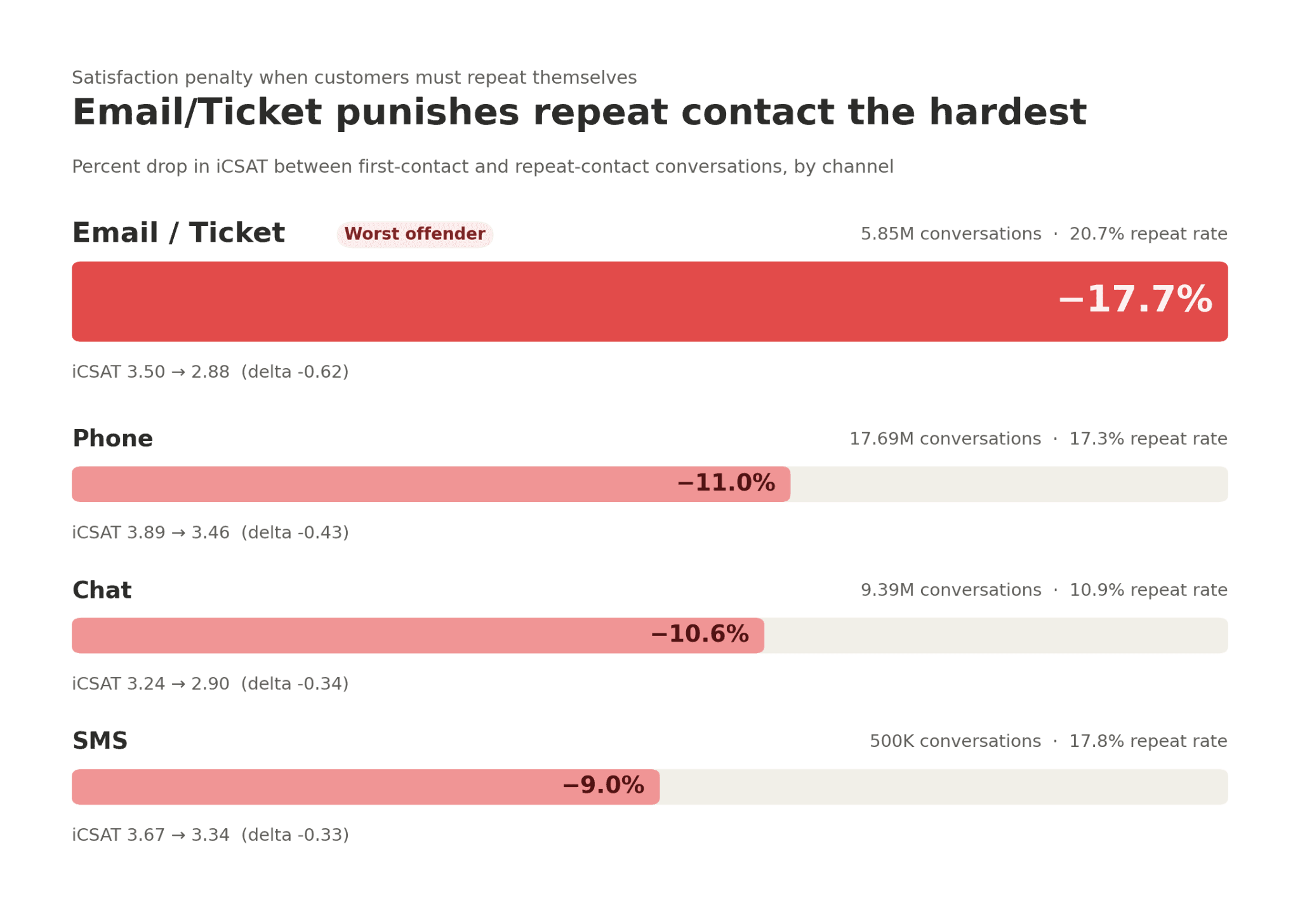
We measured what starting over costs. Across 33.4 million conversations from more than 50 organizations between January and April 2026, customers who had to open a new interaction about the same issue scored 11.2% lower in iCSAT than customers whose issue was handled in a single contact. This satisfaction penalty held across every channel. And in fact, the size changes by channel:
The channel penalty at a glance
Channel | Conversations | Repeat rate | iCSAT (repeat) | iCSAT (first) | Delta | % change |
Email / Ticket | 5,853,304 | 20.7% | 2.88 | 3.50 | -0.62 | -17.7% |
Phone | 17,694,858 | 17.3% | 3.46 | 3.89 | -0.43 | -11.0% |
Chat | 9,388,886 | 10.9% | 2.90 | 3.24 | -0.34 | -10.6% |
SMS | 499,860 | 17.8% | 3.34 | 3.67 | -0.33 | -9.0% |
A note on iCSAT: traditional CSAT captures survey responses from a small percentage of customers. iCSAT scores every conversation on sentiment, resolution, and customer effort — covering 100% of interactions, not just the ones that generate a survey response.
Email has the highest repeat rate and the steepest penalty, and the two are connected
A repeat contact in this study is not another reply on an open thread. It is the customer opening a new thread or case because the prior one closed, stalled, or failed to resolve. The customer has to rebuild context and repeat effort from scratch.
Email carried both the highest repeat rate and the steepest satisfaction penalty in the dataset. One in five email conversations (20.7%) produced a repeat contact. Those repeat conversations scored an average iCSAT of 2.88, against 3.50 for email interactions that stayed contained to a single thread. The drop was 0.62 points — a 17.7% penalty, the largest of any channel.
The structural reason is important: email's threshold for triggering a repeat contact is higher than other channels. Normal back-and-forth within a thread (customer replies, agent responds) stays inside a single conversation. A repeat contact in email means the prior thread completely failed, forcing the customer to re-engage from zero. The -17.7% is measuring total thread failure, not friction.
When the first email didn't actually resolve the issue, customers came back at 2.3x the rate. Logically, that's what has to happen — if the thread failed, the customer has no choice but to reopen it, re-explain the issue, and wait again. The cost of the first failure doesn't disappear. It lands on the second attempt.
This is the channel that's absorbing the most AI-generated responses. If automated replies close tickets without confirming resolution, the repeat rate rises, and each repeat carries the steepest penalty in the dataset.
The most damaging repeat contacts don't start with a bad interaction
This was the most counterintuitive finding in our study.
In conversations with normal sentiment, the repeat-contact penalty was -0.36 iCSAT points. In conversations that were already negative, the penalty was -0.05. The satisfaction drop was roughly 7x larger when the first interaction had been going well.
We can explain this through expectations. A customer in an already-tense conversation has priced in the friction, and unfortunately, a repeat contact just confirms what they expected. But a customer whose first interaction read as normal: polite agent, reasonable response, issue seemingly addressed, had no reason to expect a second contact. When the issue resurfaces and they have to start over, the gap between expectation and reality is widest
The operational implication is uncomfortable: the conversations that generate the most damaging repeat contacts are not the ones that look bad in QA. They're the ones that look fine but fail to actually resolve the issue. A closed ticket with a professional tone and an unresolved outcome is more dangerous than an obviously difficult interaction, because the customer's expectation was set higher.
When the first interaction was already hard, coming back makes it 3x worse
High-effort repeat contacts scored 0.50 iCSAT points below comparable first contacts. Low-effort repeat contacts scored 0.16 points lower. The penalty for coming back after a difficult interaction is 3x the penalty for coming back after an easy one.
That’s because effort and repetition don't add, they compound. The first interaction required explanation, waiting, transfers, or repeated verification. Then the customer had to come back and do it again. The second pass inherits the effort of the first and adds the cost of re-establishing context from scratch.
This has a direct routing implication. A repeat contact on a high-effort issue is a fundamentally different situation than a repeat contact on a simple one. Our data says it should be treated as a severity escalation, not a normal queue entry.
The channel that makes starting over easiest, penalizes it least
The penalty pattern across channels maps directly onto how much effort restarting requires.
In email, starting over means opening a new ticket, re-typing the issue, and re-attaching any documentation. On the phone, it means calling back, potentially waiting on hold, and re-establishing context verbally. However, with chat, this is clicking a button and typing a few sentences–and the penalty is lower, at 10.6%. The more the channel forces the customer to rebuild, the steeper the satisfaction cost when they do.
Chat's repeat-contact penalty was the smallest among the high-volume channels. That makes structural sense. But the repeat rate raises a different question.
Chat posted the lowest repeat rate in the dataset at 10.9%, roughly half of email's, despite also having the lowest first-contact resolution rate of any channel in our data. A channel that resolves the fewest issues on first contact should logically produce the most follow-up contacts… but chat produces the fewest.
This is a question this study raises but can't fully answer with this dataset. The most likely explanation is channel exit. A customer who doesn't get resolution in chat rarely returns through chat. They call, they email, or they drop the issue entirely. The repeat contact still happens, it just lands in another channel's numbers, or it doesn't happen at all because the customer gave up. Either outcome is invisible to chat's repeat rate.
But remember, repeat contact is the signal, not the root cause
When we controlled for difficulty, comparing repeat contacts against first contacts with the same resolution status and effort level, the repeat contacts actually scored slightly better. The -11.2% aggregate penalty exists because repeat contacts cluster disproportionately in the hardest, least-resolved interactions. The callback is drawn to the worst situations, not creating them.
That changes the intervention. If the callback itself were the problem, the right move would be to prevent customers from coming back — more deflection, more self-service gates. Since the callback is a symptom of a resolution failure that already happened, the right move is upstream: fix the reason they had to come back.
Repeat contact is most useful read alongside first contact resolution (FCR) and resolution scoring. FCR tells you whether the issue stayed in one interaction. Resolution scoring tells you whether it was actually settled. Repeat contact tells you whether the customer came back because they didn't agree.
What to do with this
Watch async channels first. Email and ticketing carry the steepest penalty and the highest repeat rate. Thread resolution completeness, context that survives a closed ticket, and proactive re-engagement all matter more in async channels than synchronous ones. If AI is closing email tickets, a resolution confirmation step is the highest-value addition you can make, because a closed ticket that wasn't actually resolved is the most expensive failure mode in this dataset.
Read repeat contact against effort and resolution together. A high-effort, unresolved interaction that produces a repeat is a 3x penalty situation, and a low-effort resolved one that still produces a repeat is a different problem with a different fix. The three signals compound, and reading them separately misses that.
Treat a repeat contact as a resolution failure, not a volume problem. The conventional response to a high repeat rate is to reduce inbound volume — more self-service, more deflection. But this data argues against that. Repeat contacts are a marker of broken resolution, not excess demand, and reducing them means fixing the conditions that send customers back: incomplete resolution, broken context, and issues that looked closed on the agent's screen but weren't closed from the customer's perspective.
Deflection is not resolution. This data shows the cost of the difference.
The CX industry is spending more on AI-driven deflection than at any point in its history. The metric most vendors lead with, the share of interactions that never reach a human, is rising across every channel. And in async channels, where deflection is easiest to manufacture and hardest to audit, the cost of getting it wrong is the steepest in this dataset.
A deflected interaction that was actually resolved costs nothing. A deflected interaction that closed a ticket without resolving the issue costs -17.7% in email and -11.0% on the phone — because the customer comes back, starts over, and carries the accumulated effort and broken expectations into the new interaction.
Across 33.4 million conversations, the data makes a consistent case: the most important metric in a contact center is not how many interactions were handled. It's how many customers had to come back. The organizations that drive repeat contacts down are fixing resolution and context simultaneously. The ones that celebrate deflection rates without measuring repeat contact rates are optimizing for a number that hides the most expensive failure in the operation.

