Q1 2026: 8 Releases from Last Quarter for Accountable CX



Q1 2026: 8 Releases from Last Quarter for Accountable CX
The promise of AI in CX is limited by manual processes and inaccurate measurement. This created a massive gap between bots and human agents. We saw the industry struggling to move past pilot programs and into true, accountable CX transformation. We responded by doubling down this quarter. We're thrilled to announce Eight Major Releases That Close the Gap Between AI and Accountable CX, updates across AutoQA, Virtual Agent, and Analytics. These releases radically reduce manual overhead, sharpen measurement accuracy, and bring automation to every interaction. Level AI ensures our customers lead the AI race.
Section 1: Holding Human Agents Accountable
We have always provided the tools to measure agent performance. This quarter, we made it faster, more self-serve, and capable of evaluating complex agents and customers' behaviors, where timing matters: verifying when and in what order a behavior occurred.
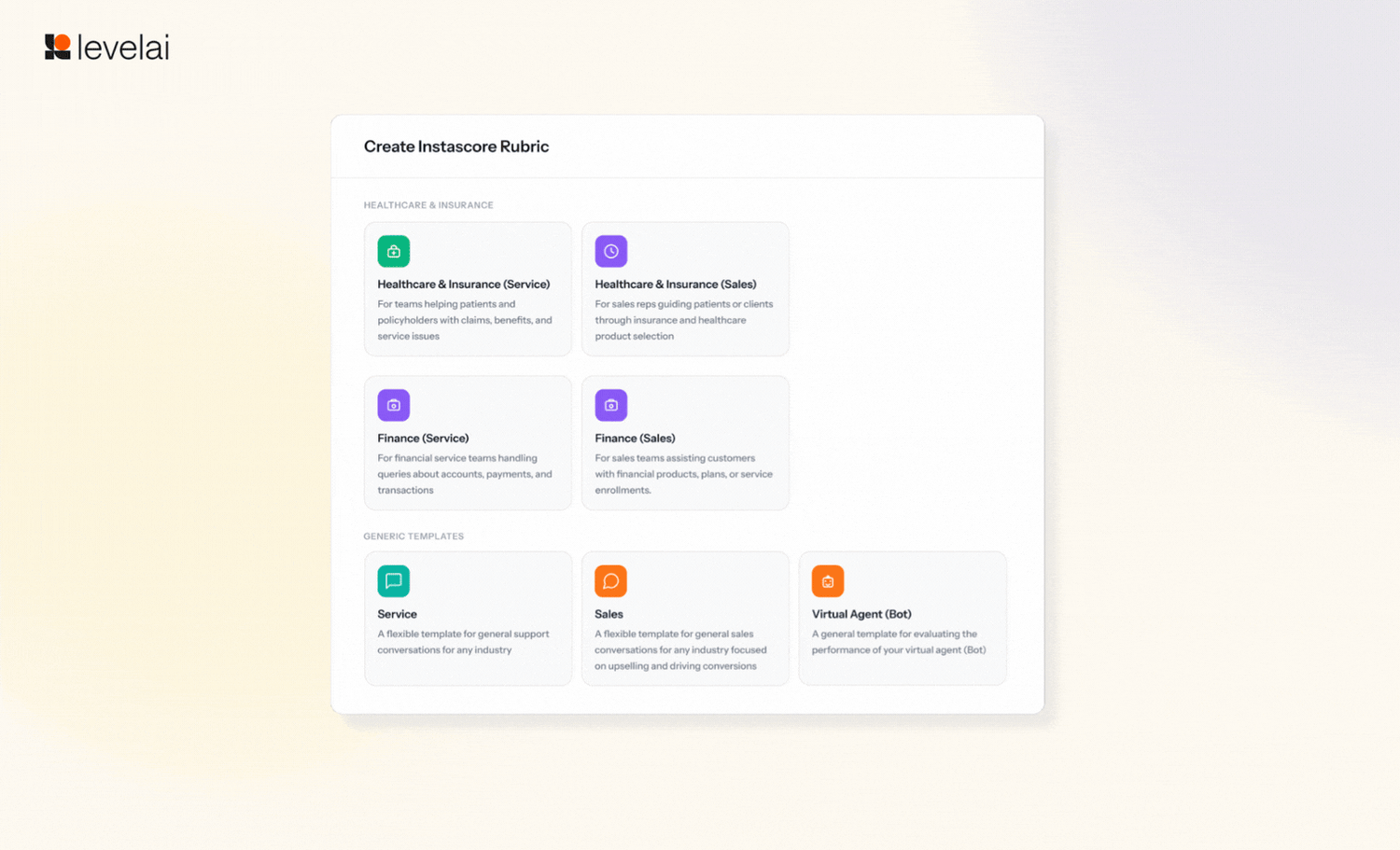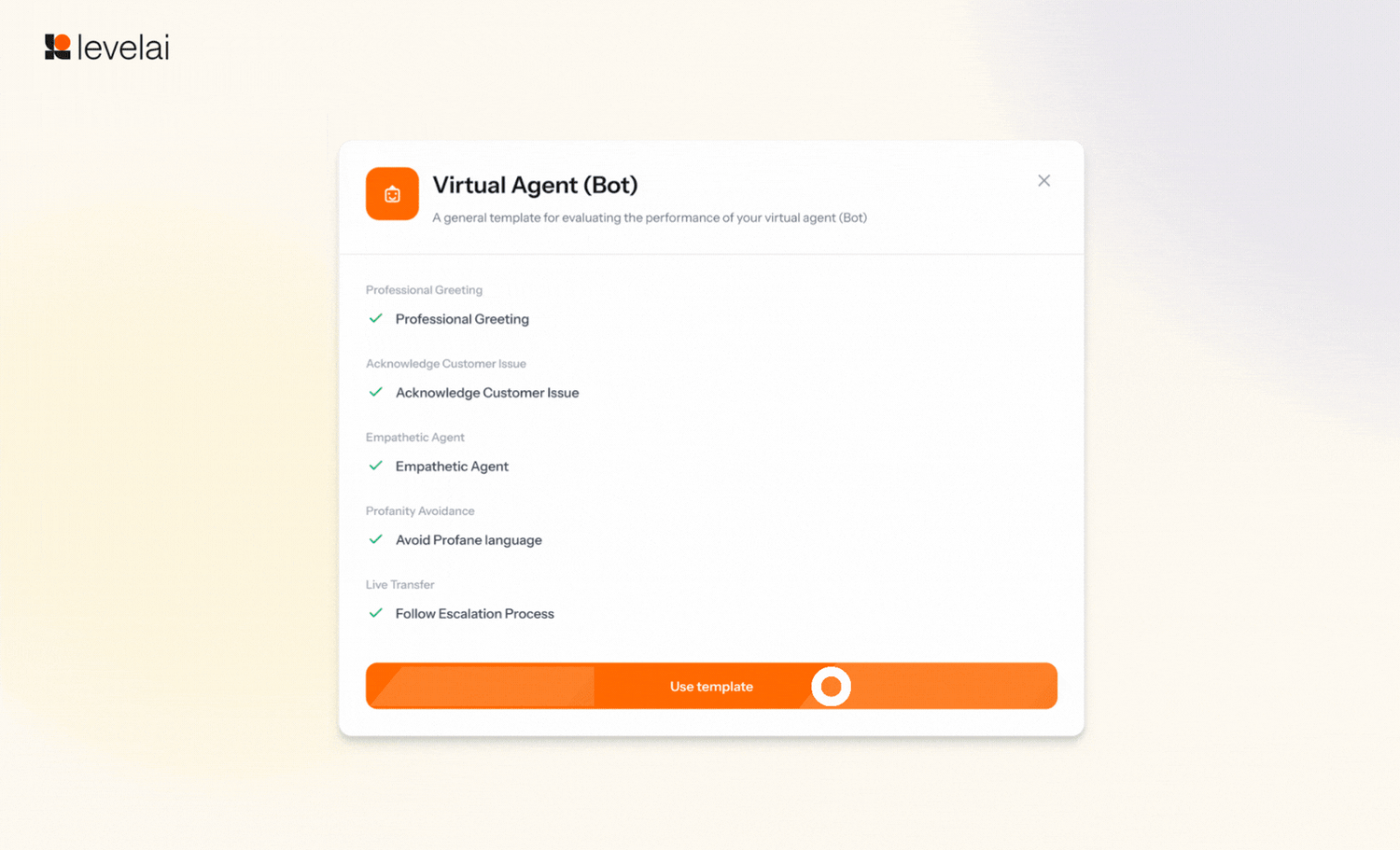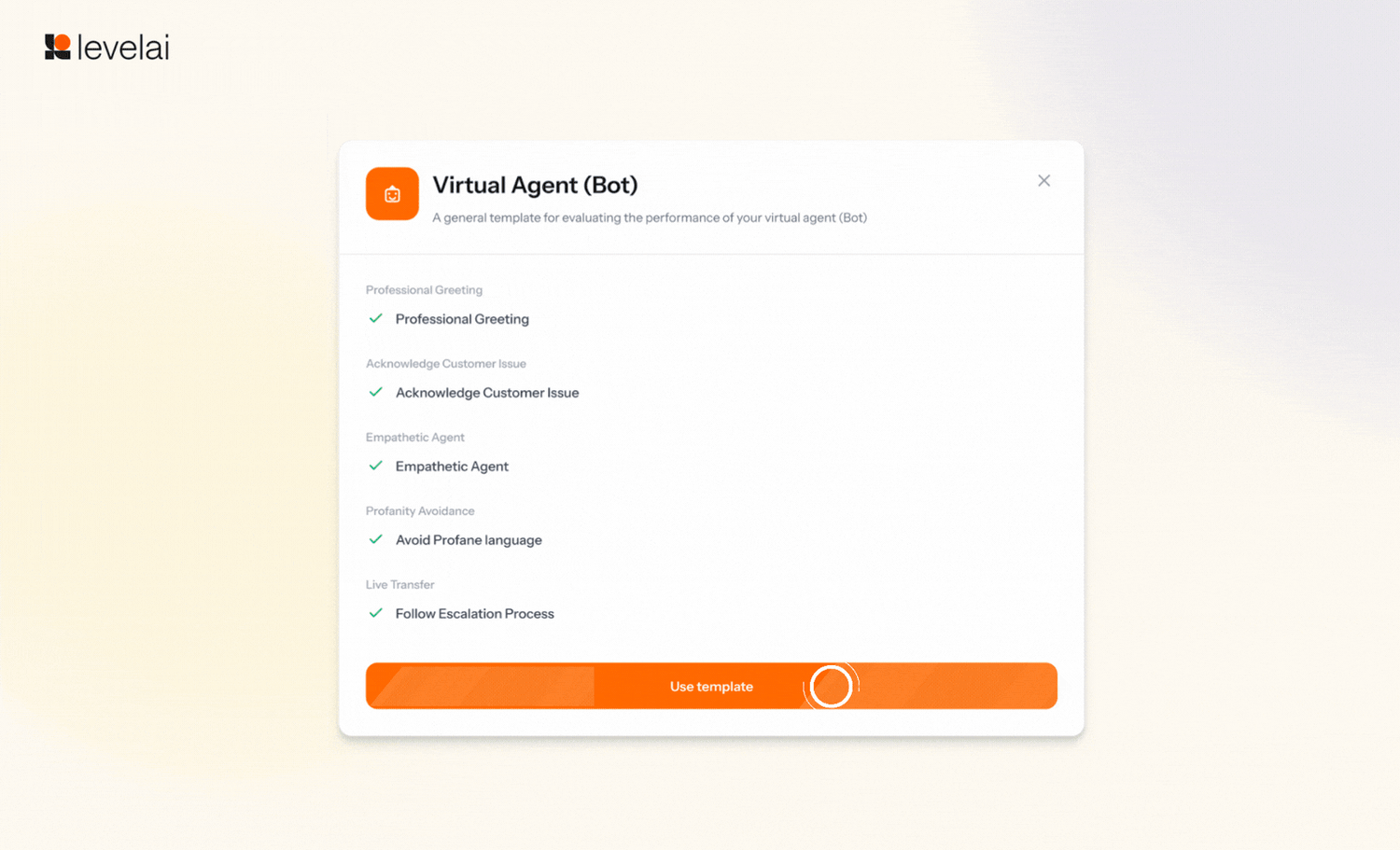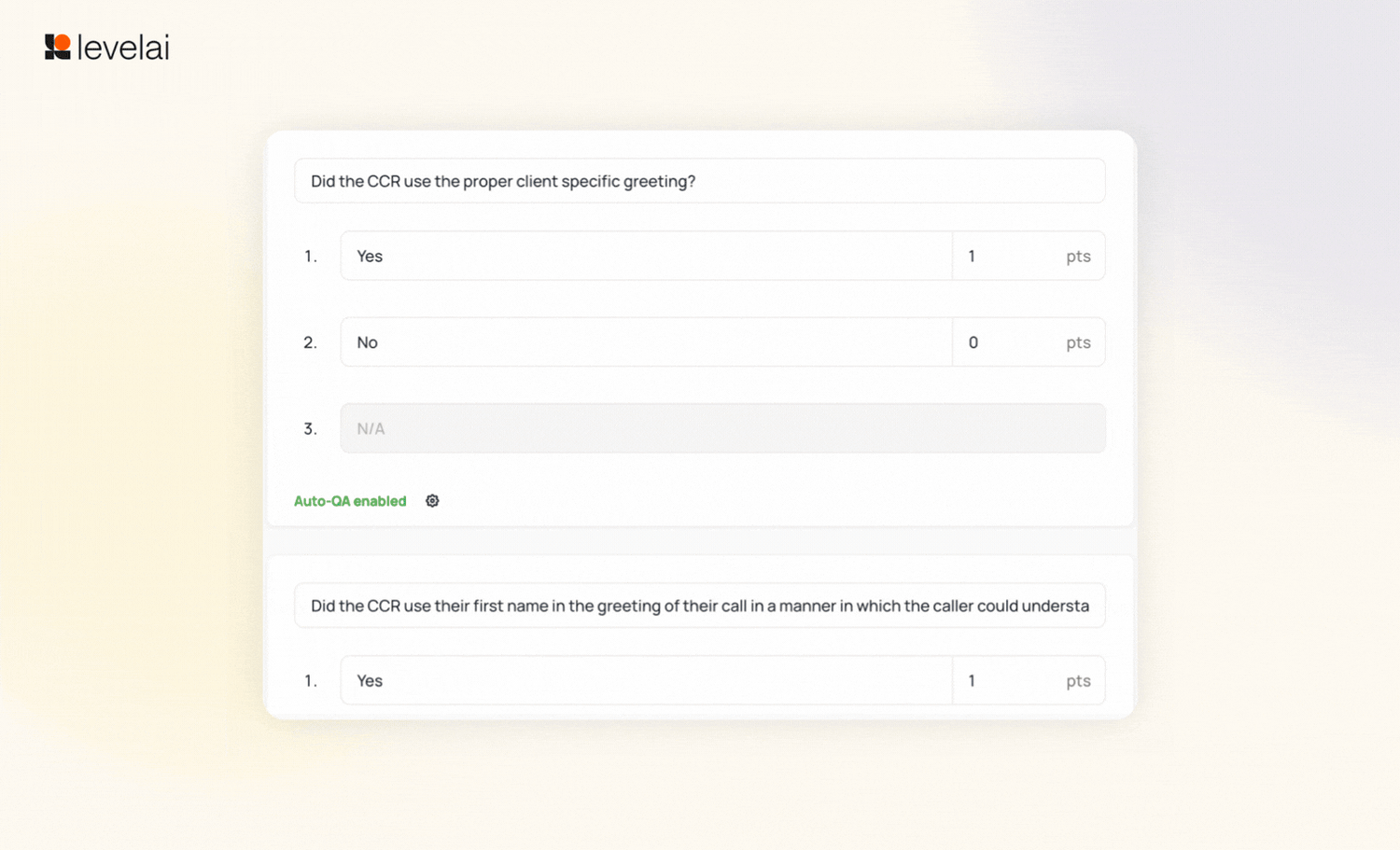
1. AI-Powered AutoQA Question Builder
Building and validating AutoQA questions has become easier than ever. Simply begin typing a question, and the builder surfaces recommendations from the existing library of questions, tags, and metric tags. Additionally, this release introduces automated rubric question generation. Simply input a draft prompt and select "Refine with AI" to generate a finalized question, significantly accelerating the rubric creation process. You can test these questions on 50 conversations before they go live, eliminating the margin for error.
With 30% of questions pre-built from the existing library and the rest drafted with AI-assisted prompting, customers complete rubric creation in a single session. The setup→review→testing→deployment cycle is gone. Teams that waited days to validate a new rubric are now live before the end of the workday.
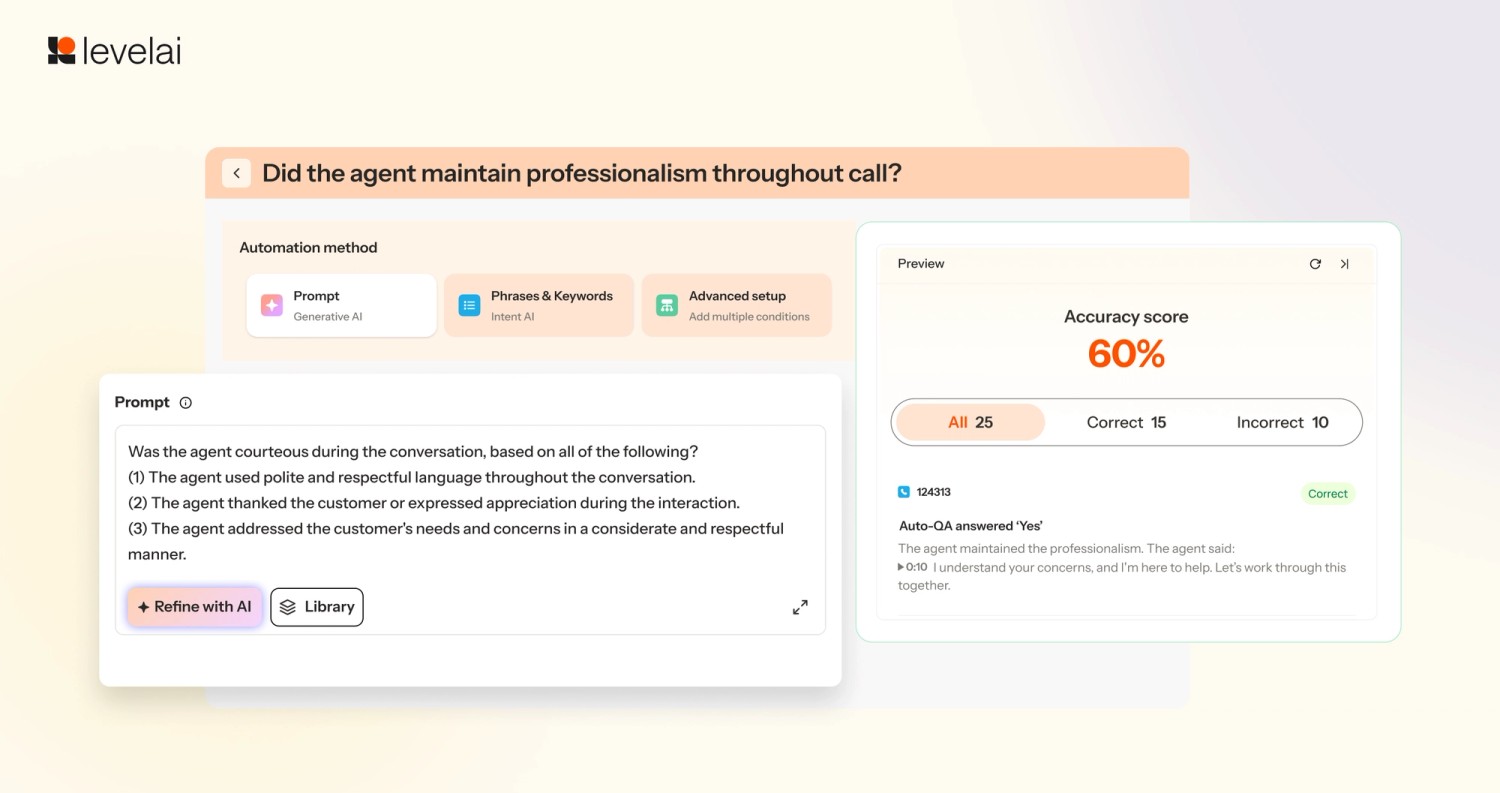
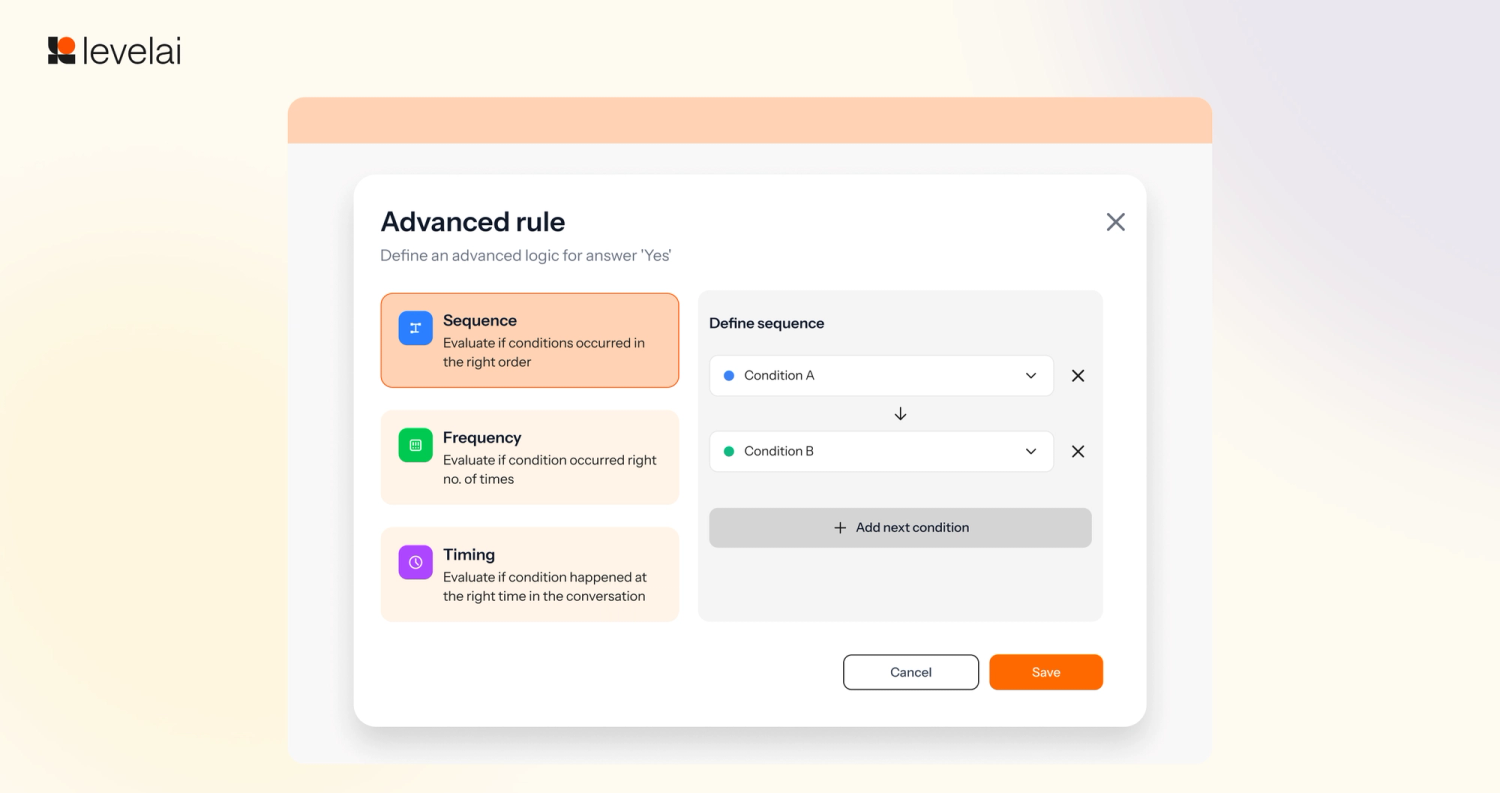
2. Sequence and Frequency Logic in AutoQA
Introducing four new logic types to confirm whether a behavior occurred: Sequence (correct order), Timing (within a defined window), Frequency (repeated behaviors), and Multiplier (YES when any or all conditions are met). Each returns a YES/NO summary with timestamped transcript evidence.
Customers are automatically analyzing complex behaviors and verifying whether agents walked customers through multi-step processes in the correct order, something that previously required a manual listener. Whether it's confirming that authentication occurred before account changes or that a disclosure was delivered before a product offer, customers can evaluate every scenario with timestamped evidence on every call.
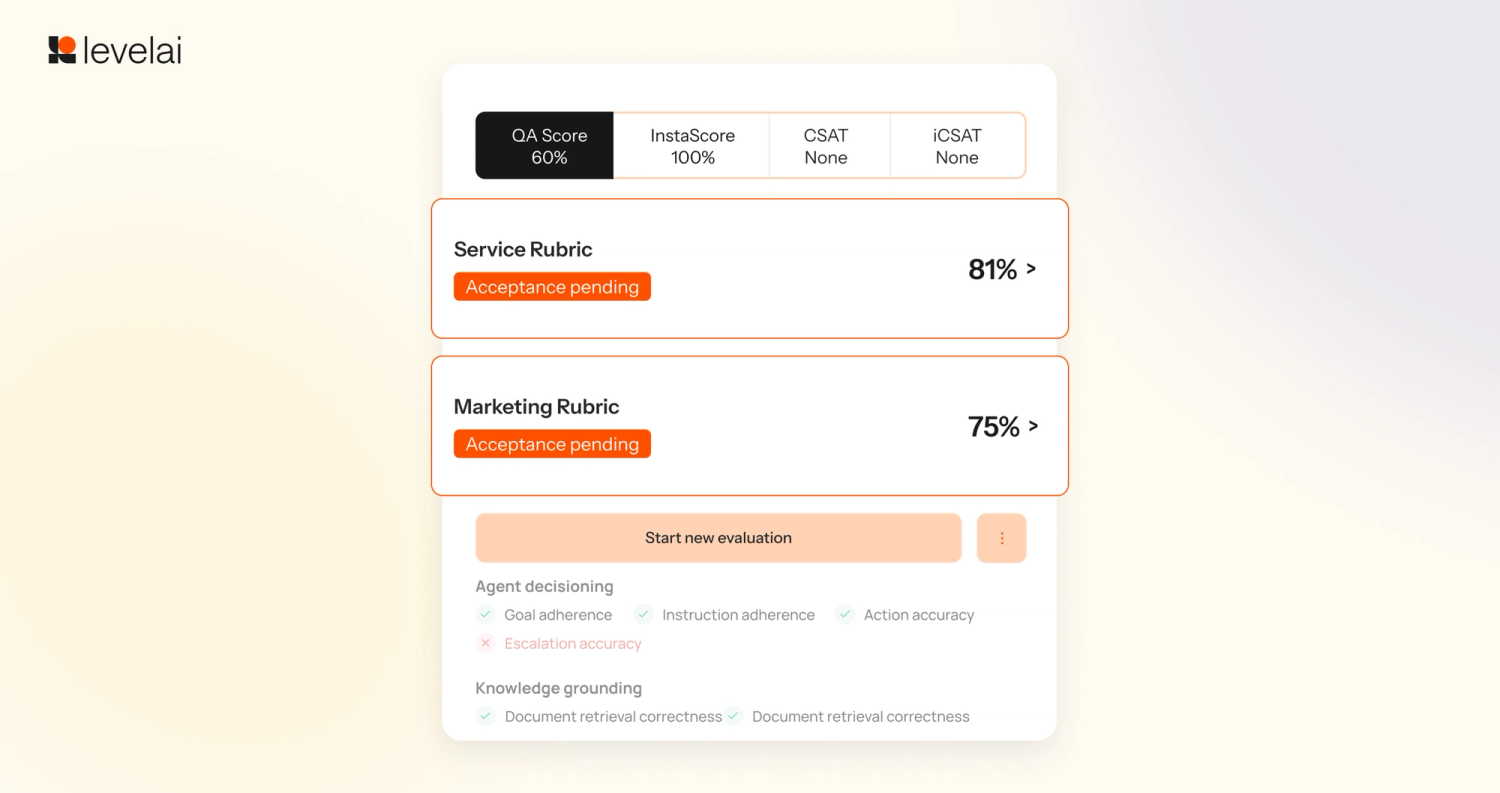
3. Multiple Evaluations per Conversation
Apply your personal rubric to the same conversation, irrespective of your team. Each evaluation is independent, generating a score, status, and audit log. All results are filterable by rubric or team in analytics. No duplicate cases, no offline coordination.
Section 2: Holding Bots Accountable
As virtual agents take on more of the conversation, the same measurement standards that apply to human agents need to apply to bots. This quarter, we extended that coverage, giving teams deterministic control over what their virtual agent does, and a dedicated evaluation framework for how well it does it.
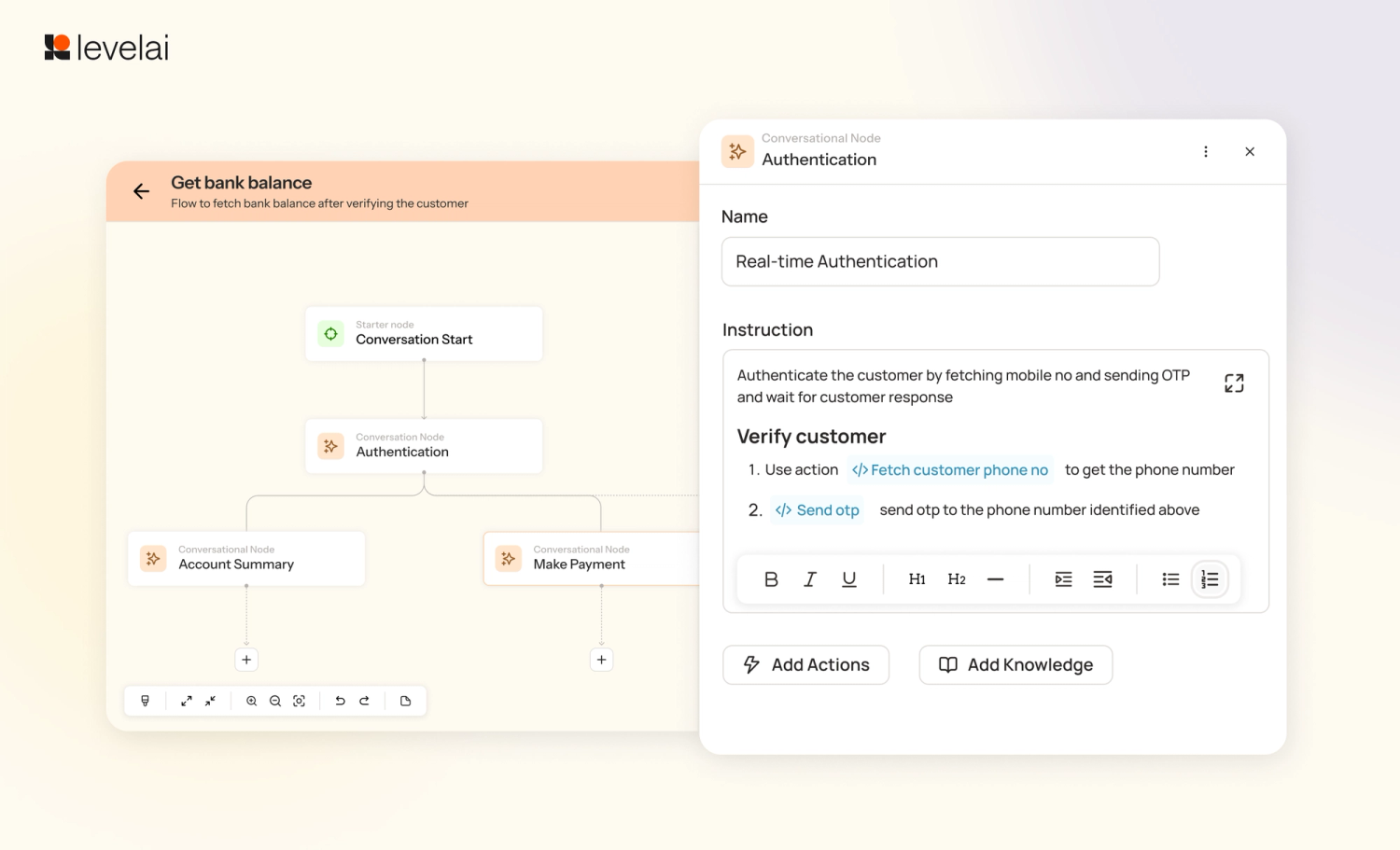
4. Canvas-Based Flows
Text-based instructions give virtual agents latitude to skip steps. Canvas-based flows remove that latitude. Admins define the exact sequence, branching conditions, and execution logic in one visual interface. This supports Pre-call, Conversational, Post-call, and Call Transfer workflows.
Financial services and healthcare customers are using Canvas-Based Flows to handle authentication, process payments, and execute post-call lead updates automatically with DNC handling and call documentation built into the workflow. These flows deliver 60% automation on routine inquiries, with compliance documentation generated on every call as part of the flow rather than as a separate manual step.
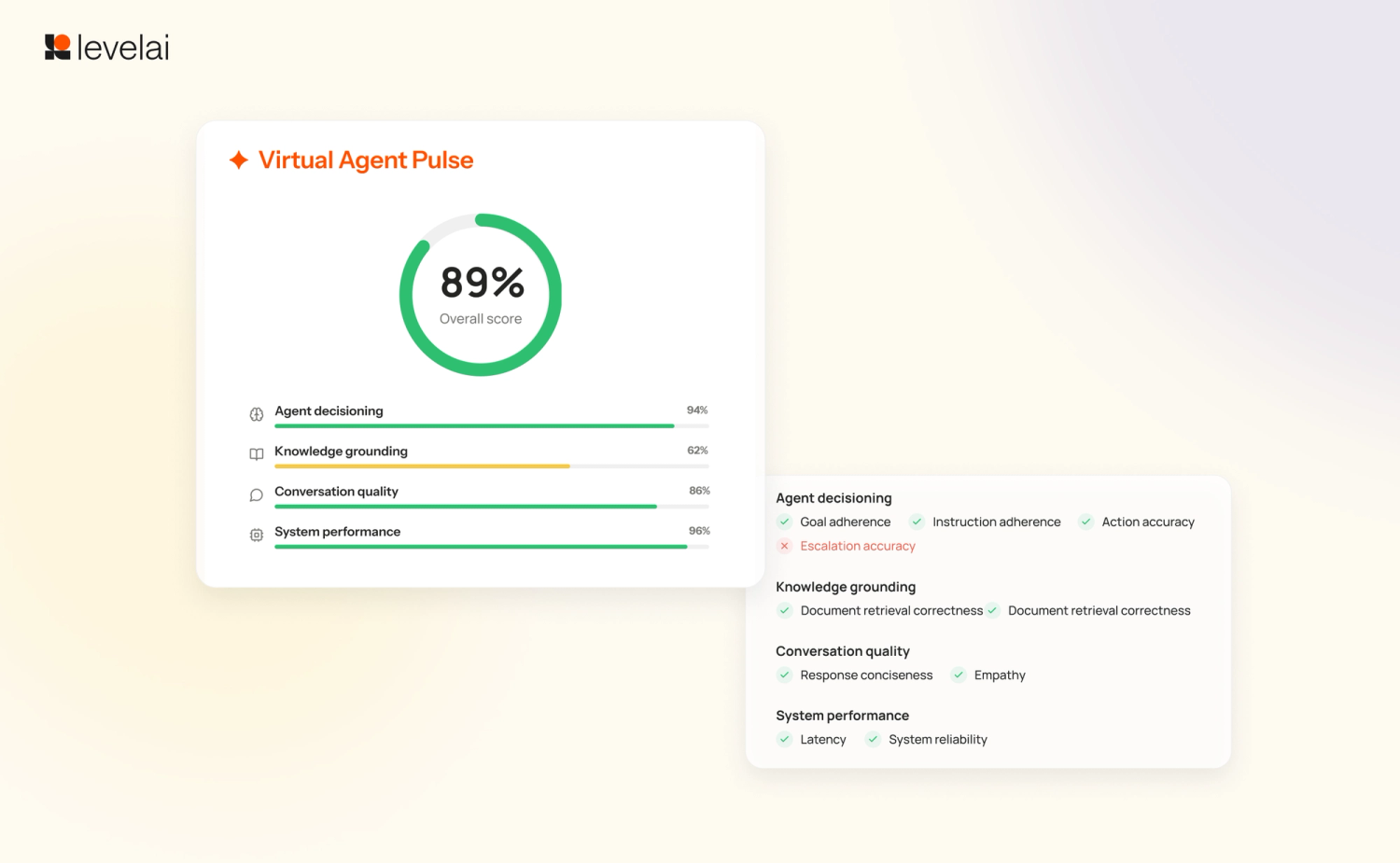
5. VA Pulse
Human-agent rubrics aren't built for bot failures: hallucinations, tool-calling errors, goal adherence drift, and premature escalations. VA Pulse scores each virtual agent interaction across three weighted dimensions and produces one interpretable Pulse Score per call with a root-cause explanation attached.
6. AutoQA Rubric for Virtual Agents
Score your Virtual Agent conversations with a pre-built Virtual Agent rubric template, just like AutoQA scores a human call. Score each of your bot conversations on resolution accuracy, escalation handling, compliance, and response quality to provide the best quality support from your bots.
Section 3: Holding our own AI accountable
Good measurement requires the AI doing the measuring to be verifiable. This quarter, we added the tools for teams to test rubric accuracy at speed and trust that what they see in Analytics reflects what actually happened — including when a score was changed and who changed it.
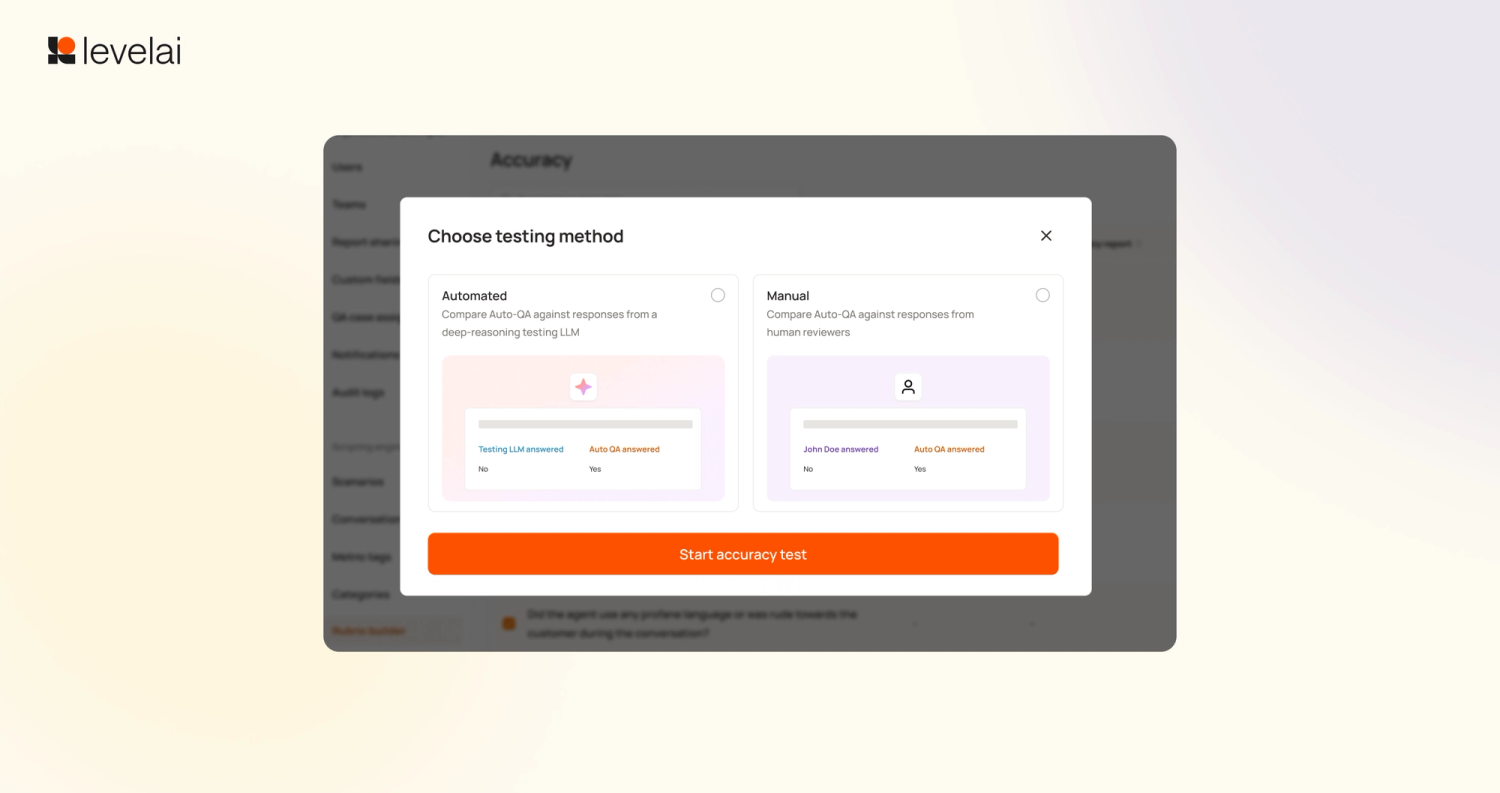
7. AutoEval for AutoQA Accuracy Testing
Testing rubric accuracy used to mean reviewing conversations manually, one at a time. AutoEval replaces that with a parallel evaluation: a deep-reasoning LLM grades the same question set as the standard AutoQA model. Where scores disagree, both answers appear side by side with the supporting transcript evidence. The run ends with a full accuracy report showing alignment rate, specific mismatches, and an overall score.
AutoEval cut time-to-value on rubric testing by 90%. Customers run multiple rubric variations in a single session with limited resources, and the deep-reasoning model provides an objective accuracy benchmark at every iteration. What previously added days to a customer's go-live timeline now adds hours.
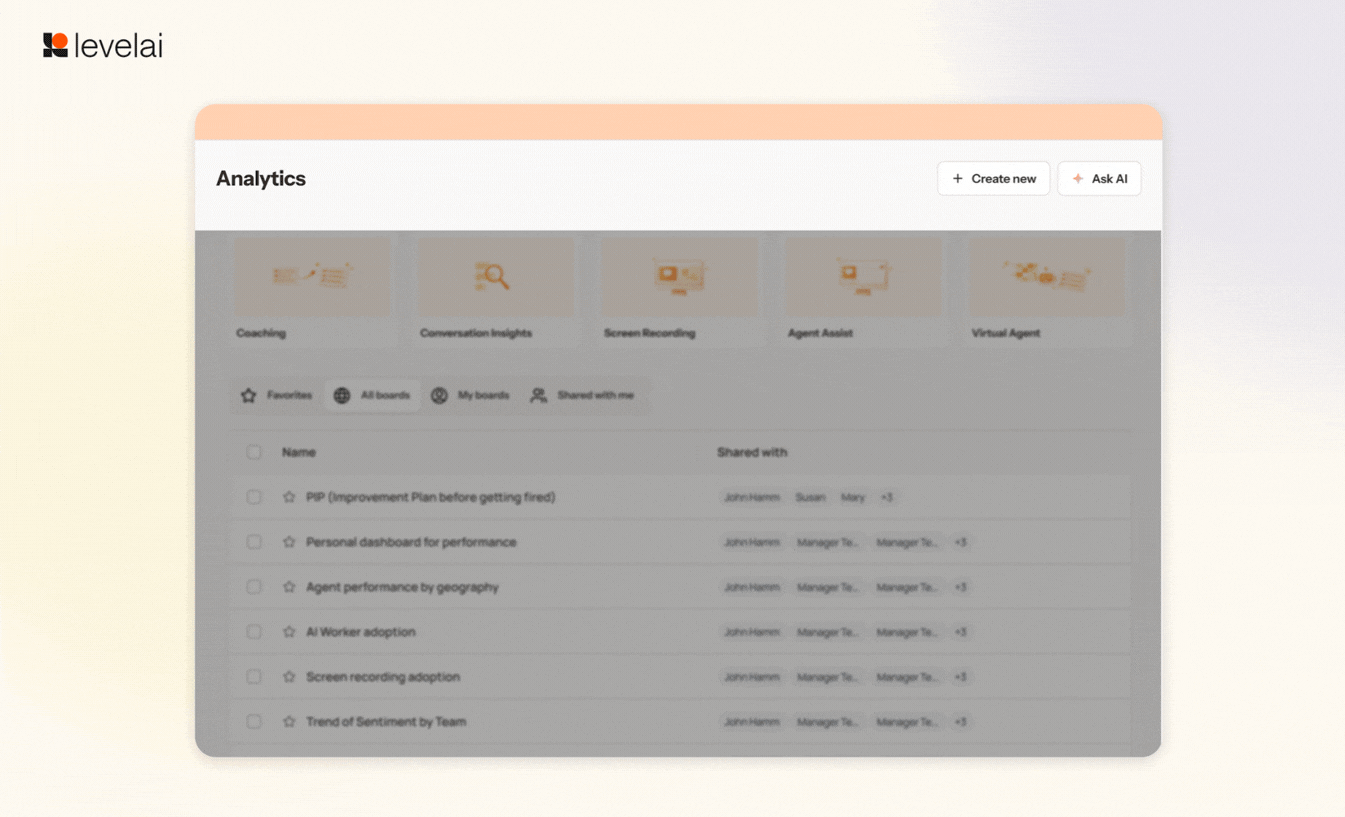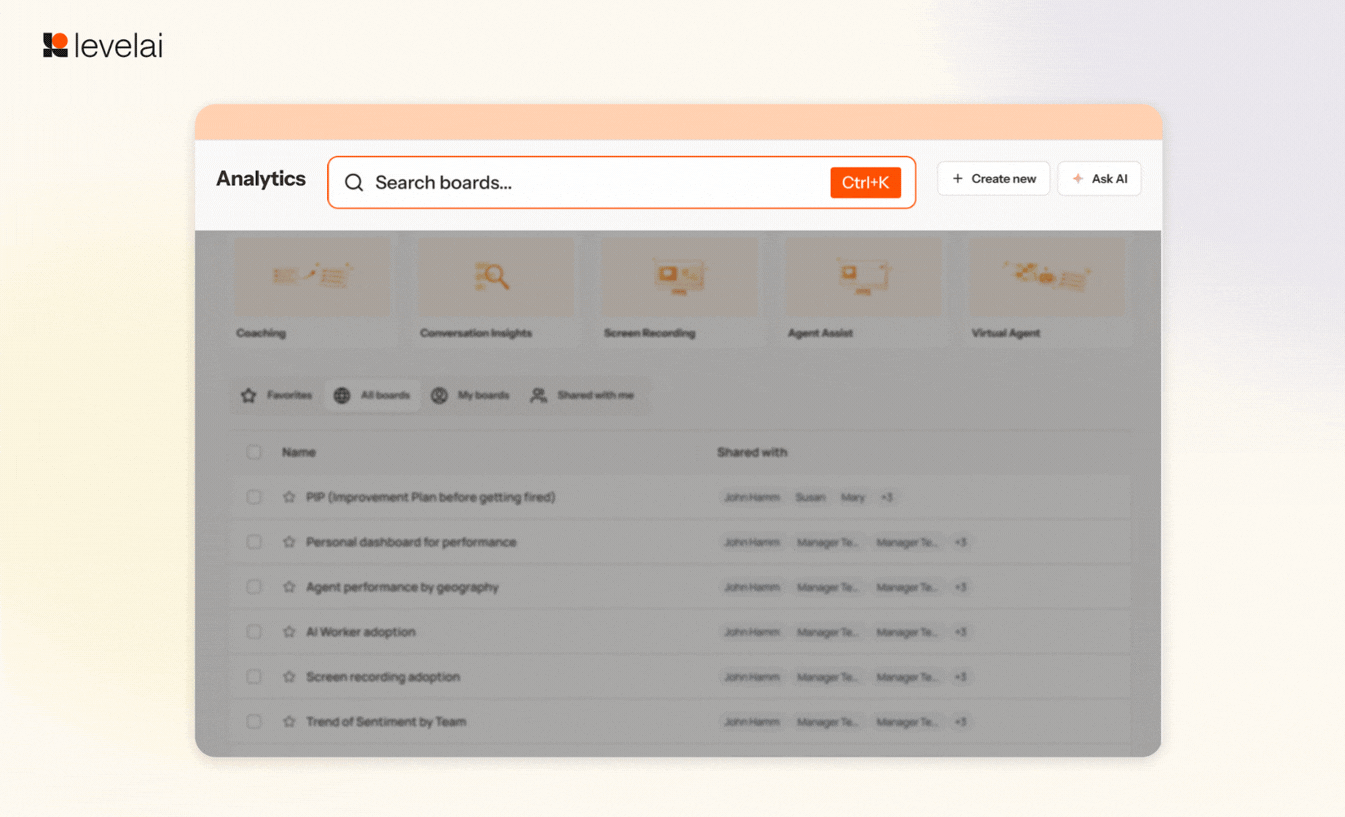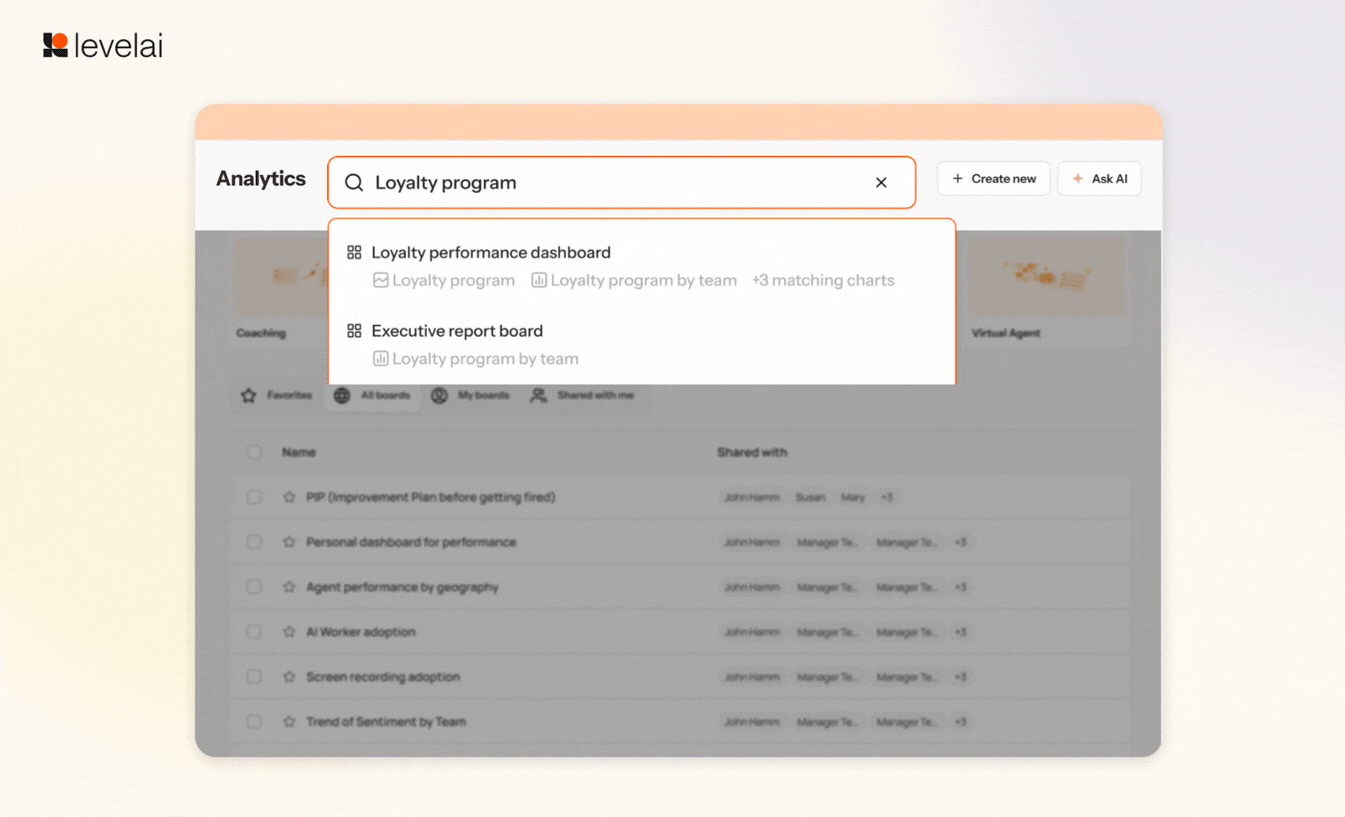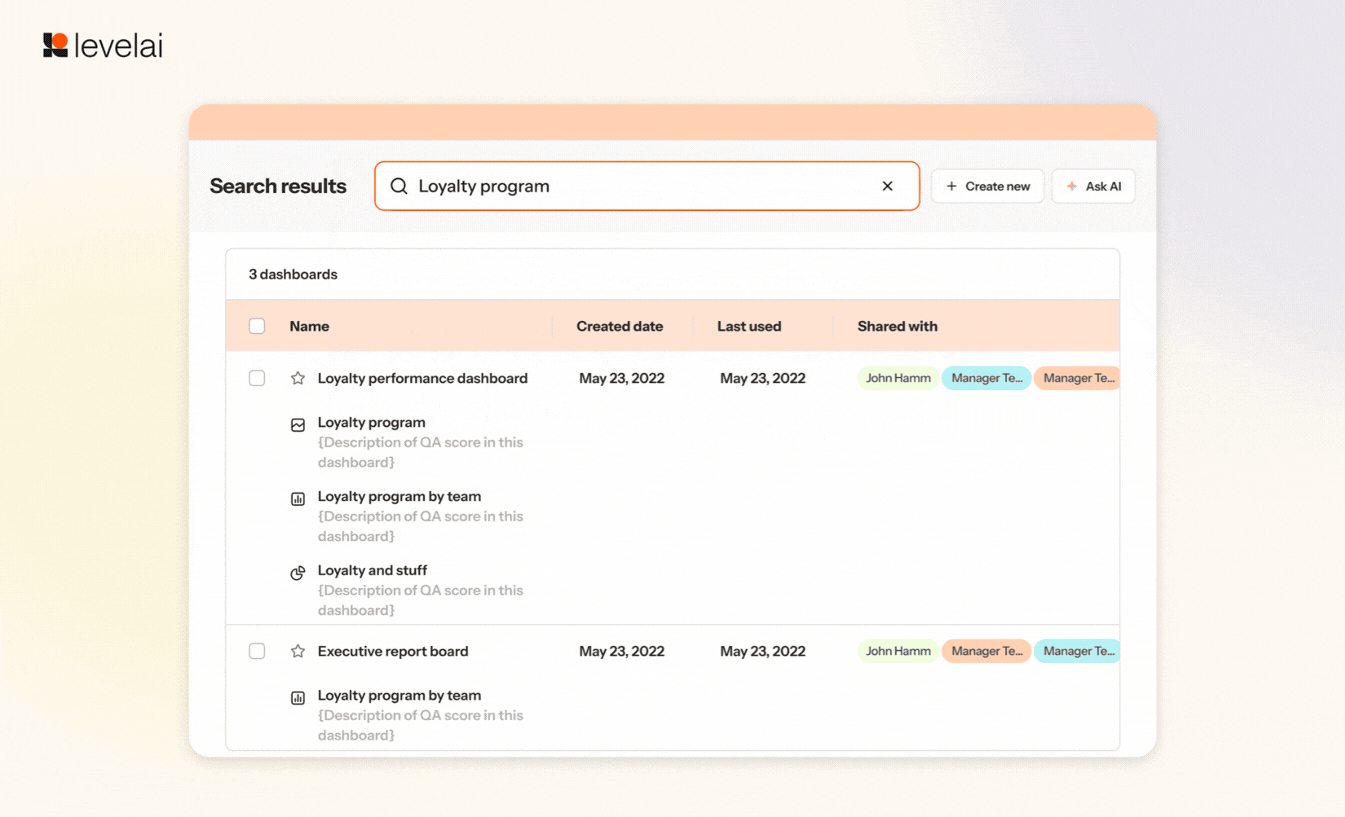
8. Analytics Redesign
The Analytics dashboard has now received a makeover to make your accessibility, flow, and readability much easier. Some of the major changes include CMD+K access from anywhere in Analytics, Group filters, indexed chart names, and descriptions alongside dashboard titles, and more.
Welcome to the platform
Level AI welcomed several new customers this quarter, including a leading real estate provider, a medical transportation platform, and some of the most recognizable retail brands in the market. We are thrilled to have them on board, and Q2 is already well underway.
Keep reading
View all













