

The explosion of voice AI has made it increasingly difficult to separate meaningful innovation from surface-level demos. Many vendors can show a voice agent that talks. Few can deliver one that feels fast, natural and reliable in a real contact-center environment.
One of the clearest differentiators of high-performing voice agents is whether the vendor truly owns the voice stack - or simply stitches together third-party components.
Performance, latency, and reliability are determined not by any one component, but by how the entire pipeline - from audio in to audio out - is designed, observed, and controlled. When that pipeline is fragmented across third-party APIs, technical issues become impossible to diagnose or fix.
This is why owning the stack is not an implementation detail. It is the prerequisite for building high-performance voice agents.
What a modern voice stack looks like
A production-grade voice agent is a multi-layered pipeline that takes in user input, processes it intelligently and returns a coherent response, all in real time. At Level AI, we manage this pipeline across five tightly integrated layers.
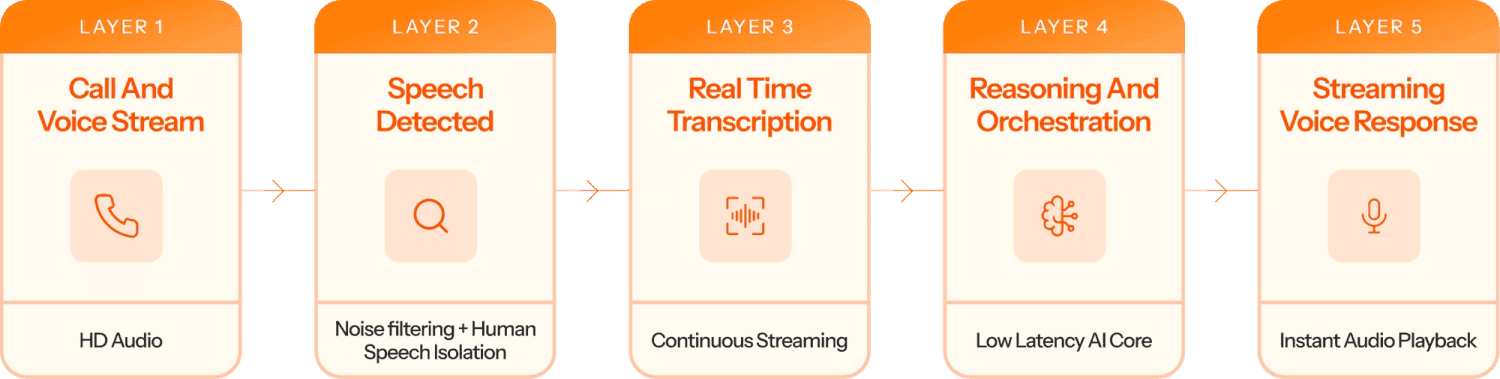
1. Connectivity and protocol layer (SIP Stack)
The entry point of the system is the telephony layer, where calls are established and audio is streamed over IP. This layer handles Session Initiation Protocol (SIP) signaling and real-time media transport. Level AI operates its own SIP stack, which allows direct control over the Voice-over-IP stream before the audio reaches the AI system. This control is critical not only for managing packet loss, jitter, and routing decisions, but also for enabling seamless call transfers to human agents over PSTN and VoIP networks.
2. Input pre-processing and Voice Activity Detection (VAD)
Before transcription begins, the system must determine whether incoming audio contains human speech or is it just background noise. This is handled by Voice Activity Detection (VAD). Poor VAD leads to background noise being considered as speech, or users being unable to interrupt the voice agent. Level AI owns this layer, enabling millisecond-level detection of speech boundaries.
3. Real-time transcription (speech-to-text)
Our Speech-to-Text (STT) layer powers the transcription of the audio stream into text. In production voice systems, transcription quality is heavily influenced by accents, speaking styles, and industry-specific vocabulary - factors that generic, one-size-fits-all models often struggle with. Any transcription errors compound quickly in voice systems. At Level AI, we operate on a model-agnostic approach - This helps us leverage both our proprietary ASR model as well as multiple other best-in-class speech models. This allows us to adapt transcription behavior to customer-specific language patterns and domains, and continuously optimize for accuracy.
4. Cognitive logic and orchestration (LLM layer)
The orchestration layer manages conversation state, applies guardrails, and routes input into the appropriate LLM logic. This layer determines when the system should respond, how it should respond, and what context it should carry forward.
5. Text-to-speech (TTS layer)
Finally, the system converts generated text back into audio. To avoid robotic pauses, Level AI optimizes TTS for both human-like voice quality and low latency. Rather than waiting for the full response to be generated, audio is synthesized and streamed back frame-by-frame as soon as the first segments are ready. In addition, our TTS setup supports multiple languages and accents, and can be personalized according to customer needs.
This entire pipeline must operate continuously, in real time, under unpredictable network and environmental conditions.
Where voice agents break—and why
Here are some recurrent failure points for voice agents
High perceived latency (“awkward silence”) that can come from multiple points in the voice pipeline—not just “slow models.” It could be due to delays in detecting end of a user’s utterance, or slowness in transcription or the LLM processing or conversion of text to audio. Without observability into the time taken by each layer, vendors can only report total response time - making it hard to isolate the root cause. At Level AI, we track millisecond-level “Time to First Byte” across layers - This makes latency traceable and controllable.
Premature cut-offs and interruption detection failures: If VAD is too aggressive, users are cut off. If VAD is too slow, the bot talks over the caller. Most third-party VAD APIs hide their internal thresholds. Because Level AI owns VAD, we can observe and tune the exact speech boundary signals that drive interruption handling, enabling more reliable interruption detection. In combination with our STT layer, this also allows us to personalize voice behavior for different accents, call types, and acoustic environments so the agent responds naturally.
Low response quality - This usually originates upstream: mistranscription, lost context, or LLM processing errors. Wrapper architectures obscure this. Level AI traces every call at the ‘turn’ level. When a response is wrong, we can identify whether the root cause was mistranscription, LLM issue, or a system prompt issue.
The Level AI advantage
Ownership is not about building everything from scratch. It is about controlling the parameters that matter. At Level AI, ownership is defined by the ability to observe, tune, and replace components without breaking the system.
SIP Layer: Owning the SIP stack helps integrate seamlessly with legacy SIP based CCaaS systems to modern gRPC/webRTC based CCaaS systems - This ensures smooth onboarding on our client side IVRs.
Deployment framework: Our modular framework allows full stack deployment in specific geographies (e.g., Frankfurt or Mumbai), reducing physical network latency and meeting data-residency requirements.
STT and TTS: We are model-agnostic and leverage both our proprietary ASR model and multiple other best-in-class providers. This gives us the ability to select the best model for each customer based on latency, domain, vocabulary, and cost.
VAD: Fully owned and tuned in-house to solve interruption handling—one of the hardest problems in voice.
LLM orchestration: Owned end to end to enforce business logic, safety guardrails, and brand-aligned behavior.
This balance of owning the critical layers while remaining flexible at the model level, is what enables superior agent performance.
“Owning the stack”: why does it matter?
Owning the voice stack means moving beyond “black-box” APIs to a model where we control the fundamental parameters of Perception (VAD), Transcription (STT), and Synthesis (TTS). It fundamentally changes what is possible by turning voice stack from an opaque pipeline into a measurable, optimizable system. Here’s what that enables:
End-to-end observability: When you own the stack, you can trace every call at each layer from VAD to STT to orchestration to TTS. Level AI’s stack could isolate failures to specific milliseconds across these layers, or conditions including noise patterns, accents, jitter.
Enabling fallbacks and graceful degradation: STT/TTS models evolve quickly, but swapping them is risky if it breaks custom logic and guardrails. A model-agnostic stack can help you switch to better models or enable fall back routing and safe-mode behaviors, for controlled degradation so a single component issue doesn’t collapse the entire experience.
Edge deployments: Processing location matters more in voice than almost any other AI domain. Physical distance introduces a latency floor that no model can overcome. Owning deployment allows us to place the entire voice stack close to callers, enabling human-like turn-taking.
Continuous improvement: By owning VAD and orchestration, we continuously refine interruption handling, accent robustness, and conversational flow. Improvements propagate across customers instead of being reset with each vendor update.
The three questions that expose wrappers
If you are evaluating a voice AI vendor, these questions separate stack owners from orchestrators:
Can you show millisecond-level telemetry for the VAD-to-STT handoff in a single call? Good answer: detailed timestamps across layers. Bad answer: aggregate latency metrics owned by third-party APIs.
Can we choose where voice processing—not just storage—is deployed? Good answer: full stack deployment in specific regions. Bad answer: a single global processing region behind a CDN.
How do you integrate new models without breaking our custom logic? Good answer: pluggable models decoupled from orchestration. Bad answer: automatic vendor updates you cannot control.
The bottom line
High-performance voice agents are systems, not demos. Latency, reliability, safety, and quality are emergent properties of the entire stack—not any single model.
Owning the stack is the only way to see, fix, and continuously improve those properties.
Everything else is noise.
Want to know more? Sign up for a demo: https://thelevel.ai/request-demo/



" transform="translate(247.297 0)" width="197.82796686746997px"/><path d="M 170.627 0 C 171.353 0 172.122 0.325 172.939 1.064 C 173.761 1.807 174.601 2.942 175.447 4.484 C 177.139 7.567 178.793 12.158 180.378 18.127 C 183.546 30.056 186.405 47.348 188.809 68.751 C 193.617 111.549 196.592 170.691 196.592 236.029 C 196.592 301.367 193.617 360.509 188.809 403.307 C 186.405 424.709 183.546 442.002 180.378 453.931 C 178.793 459.9 177.139 464.49 175.447 467.574 C 174.601 469.116 173.761 470.251 172.939 470.993 C 172.122 471.733 171.353 472.058 170.627 472.058 C 169.901 472.058 169.131 471.733 168.314 470.993 C 167.492 470.251 166.652 469.116 165.806 467.574 C 164.113 464.49 162.461 459.9 160.876 453.931 C 157.708 442.002 154.848 424.709 152.444 403.307 C 147.637 360.509 144.662 301.367 144.662 236.029 C 144.662 170.691 147.637 111.549 152.444 68.752 C 154.848 47.348 157.708 30.056 160.876 18.127 C 162.461 12.158 164.113 7.568 165.806 4.484 C 166.652 2.942 167.492 1.807 168.314 1.064 C 169.131 0.325 169.901 0 170.627 0 Z M 71.713 0 C 62.009 0 52.656 6.435 44.052 18.342 C 35.457 30.238 27.69 47.491 21.156 68.871 C 8.091 111.621 0 170.721 0 236.029 C 0 301.337 8.091 360.436 21.156 403.187 C 27.69 424.566 35.457 441.82 44.052 453.715 C 52.656 465.623 62.009 472.058 71.713 472.058 C 81.416 472.058 90.77 465.623 99.373 453.715 C 107.969 441.82 115.736 424.566 122.269 403.187 C 135.334 360.436 143.425 301.337 143.425 236.029 C 143.425 170.721 135.334 111.621 122.269 68.871 C 115.736 47.492 107.969 30.238 99.373 18.342 C 90.77 6.435 81.416 0 71.713 0 Z" fill="transparent" height="472.05786706056097px" id="AtqcuIS6E" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="1.845" stroke="rgb(146, 146, 146)" transform="translate(102.538 0)" width="196.59214365028447px"/><path d="M 123.024 0 C 89.215 0 58.469 26.24 36.139 68.983 C 13.822 111.702 0 170.76 0 236.029 C 0 301.298 13.822 360.356 36.139 403.075 C 58.469 445.817 89.215 472.058 123.024 472.058 C 156.834 472.058 187.58 445.817 209.91 403.075 C 232.226 360.356 246.048 301.298 246.049 236.029 C 246.049 170.76 232.226 111.702 209.91 68.983 C 187.58 26.24 156.834 0 123.024 0 Z" fill="transparent" height="472.05786706056097px" id="nKu1rpt6g" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="1.845" stroke="rgb(146, 146, 146)" width="246.04881024096358px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.38193205317657px" id="qx6powAle" transform="translate(423.219 103.185)" width="12.863448795180375px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.38193205317657px" id="NK9e8zC6o" transform="translate(293.204 255.173)" width="12.86344879517992px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.38193205317657px" id="GMpYPNX_6" transform="translate(427.575 329.773)" width="12.863448795180375px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.38193205317657px" id="xEa1_xTe3" transform="translate(99.187 154.777)" width="12.863448795180375px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.38193205317475px" id="RVMs3MQ2J" transform="translate(111.25 382.759)" width="12.863448795181284px"/><path d="M 0 6.691 C 0 2.996 2.88 0 6.432 0 C 9.984 0 12.863 2.996 12.863 6.691 C 12.863 10.386 9.984 13.382 6.432 13.382 C 2.88 13.382 0 10.386 0 6.691 Z" fill="rgb(254, 80, 0)" height="13.381932053172932px" id="ka1rTUarQ" transform="translate(28.818 63.445)" width="12.863448795180375px"/></g></svg>)