Releasing Our Parallel Multi-Modal Architecture for Virtual Agents: The New Standard for Human-Quality AI



Key Takeaways
1. Most AI voice agents rely on a single model to handle everything (listening, understanding, searching, replying, safety checks). This drags down AI agent performance with slow responses and frequent errors. It is like asking a brain surgeon to put on a band-aid.
2. Level AI builds AI voice agents using many small models, each trained for one job. Simple tasks run on fast, lightweight models, and only the final reply uses a bigger model. This boosts AI agent performance without wasting compute capacity.
3. To keep AI voice agents fast, all models run at the same time, not one after the other. Safety checks, understanding the question, and pulling context happen together in about 300 milliseconds. This is what real-world AI agent performance should feel like, no delay for the customer.
4. This setup delivers five clear wins for AI agent performance: cleaner instructions mean fewer mistakes, near-zero delay, automatic backups if something fails, easy upgrades without rebuilding the system, and 80% less maintenance because agent feedback trains the AI voice agents over time.
5. When picking AI voice agents, ask three questions to judge AI agent performance: Do you use one model per job? Does the voice part run alongside the thinking part? Can you swap any single model without rebuilding everything? If the answer is no, the system will break or fall behind quickly.
Why the all-in-one model is a technical liability for enterprise CX
Forcing a single large language model (LLM) to do everything in a voice agent: transcribe voice, detect intent, follow SOPs, or authenticate a customer - is a recipe for high latency and low reliability. It creates the following problems:
- When one model handles intent, retrieval, and safety simultaneously, accuracy takes a hit as we try the one size fits all approach.
- Using a complex reasoning model to handle simple tasks (like intent classification) is like hiring a neurosurgeon to put on a band-aid. It’s inefficient and expensive.
Now think about how your own mind works when someone asks you a question. Your brain doesn't just fire one single neuron. It’s a sophisticated, parallelized operation: one part of your mind instantly decodes the speech(audio to text), another identifies the person's intent, another retrieves a specific memory, and deploys a social filter to ensure your response is appropriate. Some of these actions are reflexive and lightning-fast, while others require deep, slow reasoning.
This is why we built our AI virtual agent from the ground up, powered by a modular, multi-model architecture to avoid the fundamental limitations of the monolithic approach.
Deconstructing the Level AI architecture
We have engineered our system as a composite of specialized models, each optimized for a distinct phase of the conversation lifecycle to maximize speed and precision:
The voice stack and input processing
- Speech-to-text (STT): We use dedicated models to convert streaming audio bytes from the telephony layer into text in real-time.
- Voice activity & endpoint detection (VAD): These models run in parallel with STT to suppress background noise and determine exactly when a user has finished speaking. This ensures we don't cut off the user or wait too long to respond.
Input guardrails for safety
- Security layer: Designed for safeguarding your virtual agent against malicious attacks, the system uses a lightweight classifier model to detect and block unsafe inputs before processing.
Intent and contextual routing
- Intent detection & routing: We utilize small language models (SLMs) to analyze the query to determine intent, and load the correct sub-agent instructions.
- Contextual query generation: In parallel with routing, the SLM also analyzes past turns in the conversation. It reformulates the query to include necessary historical context, ensuring our retrieval process is pinpoint accurate.
Knowledge retrieval
- Knowledge base access: If the user query requires getting a response from the knowledge base, then the retrieval tool is used to fetch the relevant documents
Query execution and response generation
- Deterministic vs. Agentic workflow execution: For structured tasks like user authentication, we use a deterministic engine for step-by-step logic. For scenarios requiring more flexibility, we trigger sub agent activation.
- Main response generation: We use an LLM to synthesize the final, human-sounding response. This is the only stage where we allocate a higher latency budget (600-800ms).
- Output guardrails: We run a final safety check using lightweight models to ensure the generated response contains no sensitive information or hallucinations before it is streamed back to the voice stack.
Post-conversation processing
- Asynchronous logging & summarization: After the turn is complete, we run models for summarization and response classification. As required, this data is logged into CRMs and/or other systems of record.
With a suite of specialized models at our disposal, the next challenge is deciding which tool is right for the task.
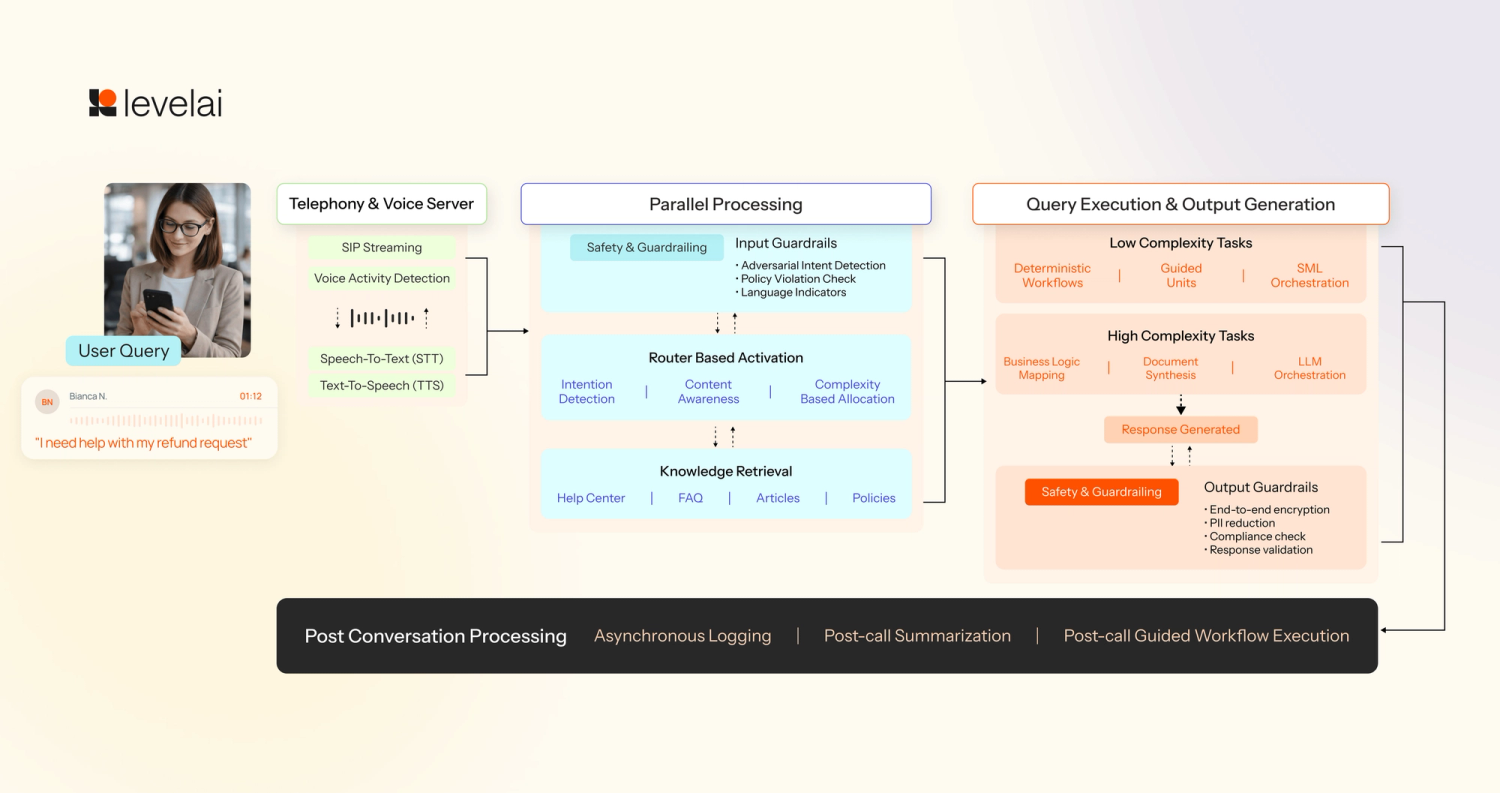
Intelligent orchestration: Level AI’s framework for model selection
The true differentiator isn't just having multiple models; it’s how we orchestrate them at runtime. We use a ‘Graph Execution’ approach where nodes run simultaneously rather than a linear sequence. Each node in our execution graph consumes a portion of that budget, and we rely on two core strategies to achieve this:
- Strategic parallelization: We don't process conversations in a linear direction. Instead, our platform activates multiple models simultaneously. For example, while our Input Guardrails are checking for safety, our Intent Router and Contextual Query models are already triggered in parallel. This allows us to complete three or four complex background tasks within the same 300ms window, providing the query execution layer with all the context it needs to respond without the customer ever feeling the processing lag.
- Complexity-based allocation: Our platform allocates computational horsepower based on the specific requirements of the sub-task:
- Low-complexity, high-speed tasks: For intent routing and contextual query reformulation, we prioritize speed. These tasks trigger in parallel and complete within ~300ms by deploying small language models (SLMs) that offer the optimal trade-off between a small computational footprint and high reliability for narrow tasks.
- High-complexity reasoning: The main response generation requires a deeper understanding of business logic and document synthesis. For this, we allocate a larger portion of our latency budget ~600-800ms, to leverage more powerful models.
- Voice accuracy benchmarks: For our voice stack, the criteria shift toward environmental robustness. We select models based on their ability to handle real-world scenarios like background noise, network jitter, and packet drops, ensuring that transcription and endpointing remain accurate even under poor connection conditions.
By orchestrating these models in a parallel graph, we ensure that the cost of intelligence or automation never comes at the price of a natural, fluid conversation.
The benefits of the Level AI multi-model strategy
This architectural choice of the Level AI platform provides four distinct advantages for the modern contact center:
- Elimination of instruction bloat: When you force one model to do everything, the instructions become cluttered. This leads to higher error rates. By giving each task a dedicated model, we keep the system focused and much more reliable.
- Achieve perceptual zero latency: Our proprietary SIP/Voice stack works in tandem with our proprietary models to eliminate the robotic lag that kills customer trust.
- Ensure reliability at scale: Because our system is modular, we have automated fallbacks. If a specific model or node fails, an equally powerful backup triggers immediately.
- Achieve infinite swappability: We can upgrade the reasoning model as soon as a better version is released without having to rebuild the transcription or routing layers.
- Reduce 80% of maintenance overheads: As Level AI unifies these models with human-data foundations, a manager’s thumbs up on a human call acts as a direct training signal to our virtual agent.
Modularity is the new benchmark for enterprise-grade CX
To ensure you are investing in a system that can handle the complexity of modern enterprise service, start with these three benchmarks:
- How do you prevent instruction bloat? If a vendor uses one model to handle every signal simultaneously, expect higher hallucination rates.
- Does your voice stack run in parallel with your reasoning engine? If the system processes tasks linearly, the cumulative delay will frustrate your customers and lead to high abandonment.
- Can you swap individual models without retraining the entire bot? If the answer is no, you are buying a brittle system that will be outdated the moment a more efficient model is released.
At Level AI we are releasing more than just a bot, we are powering automation that is continuously optimized via human-AI feedback loops. By mirroring the modularity of the human mind, we have created an architecture that is flexible where you want it, but strict where you need it. This modularity is how we ensure that every interaction, no matter how complex, meets your brand's elite standards for human-quality service.
Talk to us to learn how you can deploy human-grade automation to deliver growth driving experiences at scale. Book a Demo
Frequently Asked Questions
Q1. What are the benefits of using a multi-agent architecture for improving AI agent performance compared to a single AI voice agent?
A. A multi-agent setup gives each task its own dedicated model, which is the biggest unlock for AI agent performance. When one model handles transcription, intent, retrieval, safety, and response together, instructions get cluttered and errors rise. Modular AI voice agents avoid this. Level AI's AI Virtual Agent delivers five clear wins: no instruction bloat, near-zero perceived latency, automatic fallbacks, easy model swaps, and 80% lower maintenance through human feedback loops.
Q2. What are the biggest challenges in deploying multi-agent AI voice agents in a production environment?
A. The blog flags three core challenges. First, latency, since linear processing makes AI voice agents feel slow and drives call abandonment. Second, environmental robustness, where AI agent performance must hold up against background noise, jitter, and packet drops. Third, flexibility, because vendors that bundle every signal into one model end up with brittle systems that cannot be upgraded as better models emerge.
Q3. How do multi-agent AI systems manage memory, context, and AI agent performance across tasks?
A. Level AI runs a Contextual Query Generation step in parallel with intent detection. A small language model reformulates the query using past turns so retrieval is pinpoint accurate. This keeps AI agent performance sharp. After the call, async summarization and response classification run in the background and log into CRMs, giving AI voice agents both real-time context and a long-term memory trail.
Q4. What infrastructure is required to support production-ready AI voice agents and multi-agent systems?
A. Production-ready AI voice agents need a proprietary SIP and voice stack, a Graph Execution runtime where nodes run in parallel, a mix of small language models for fast tasks and larger LLMs for reasoning, lightweight classifiers for input and output safety, and automated fallbacks at every node. All of this is unified by Level AI's Human-Data Foundation, which feeds agent feedback back into the system to keep AI agent performance improving.
Q5. When should businesses use multi-agent AI systems instead of a single AI voice agent?
A. The moment you need real-time conversation at scale. A single AI voice agent model can work for narrow use cases, but it breaks down when speed, accuracy, and safety all matter together. If your contact center needs sub-second responses, reliable safety guardrails, and the ability to upgrade individual capabilities over time, a multi-agent system is the right call. The trigger to switch is simple: lag, hallucinations, or models you cannot upgrade without rebuilding everything.
Q.6. What are the top real-world applications of multi-agent AI systems and AI voice agents?A. The blog frames the main application as enterprise contact center automation. AI voice agents handle structured tasks like user authentication through deterministic workflows, while flexible scenarios trigger sub-agent activation for open-ended reasoning. Level AI also runs post-conversation summarization and response classification, with results logged into CRMs. The broader theme is what the blog calls Intelligence Automation Loops, making multi-agent AI voice agents ideal for any high-volume customer experience use case where speed, reliability, and brand-quality service all matter at once.
Keep reading
View all














